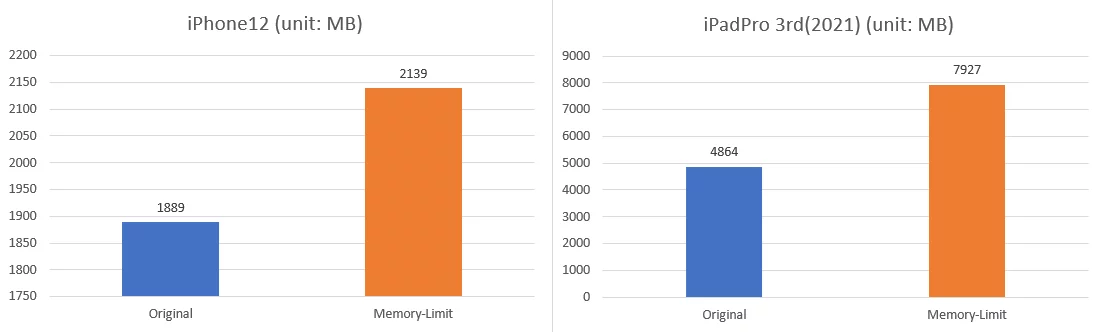
远程构建是UE中非常方便好用的一种打包IOS方式,能够只在Mac上编译代码,不COOK资源,能够极大地降低对于Mac硬件的需求。
而且,Mac的售价颇高,传统模式下,如果需要部署多个独立的IOS包构建流程,通常就需要采购多台独立的Mac机器分别部署,硬件成本较高。
况且,IOS的开发环境往往需要随着IOS系统迭代进行更新。每年WWDC发布新版本IOS,就会需要新版本的XCode支持,新版本XCode又依赖新版本的MacOS,套娃式的链式依赖。如果Mac的构建环境增多,那么更新这些机器的构建环境也会变为一个繁琐的重复任务。
远程构建IOS也能够比较好的解决这个问题,一台独立的Mac,可以同时给多个IOS构建流程提供支持,如果需要更新环境也只需要处理一台即可。而且编译代码的耗时相对固定,且能够进行增量编译,理论上来说只要不是所有的机器同时执行全量编译,那么对于Mac的性能压力就没有那么大。
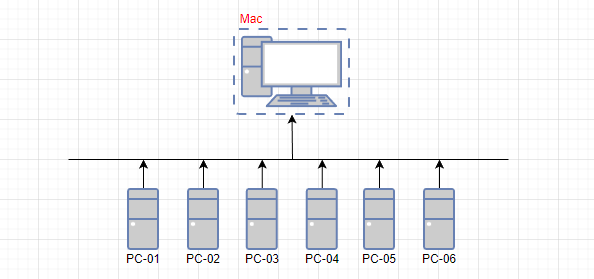
博客中也有开启远程构建IOS的文章:UE 开发笔记:Mac/iOS 篇,可以参考基础配置启用。
但UE默认实现的IOS远程构建在实际使用中也存在不少的问题,无法实现从部署到构建全自动化流程,本篇文章会针对远程构建在实际的工程应用中痛点进行优化。