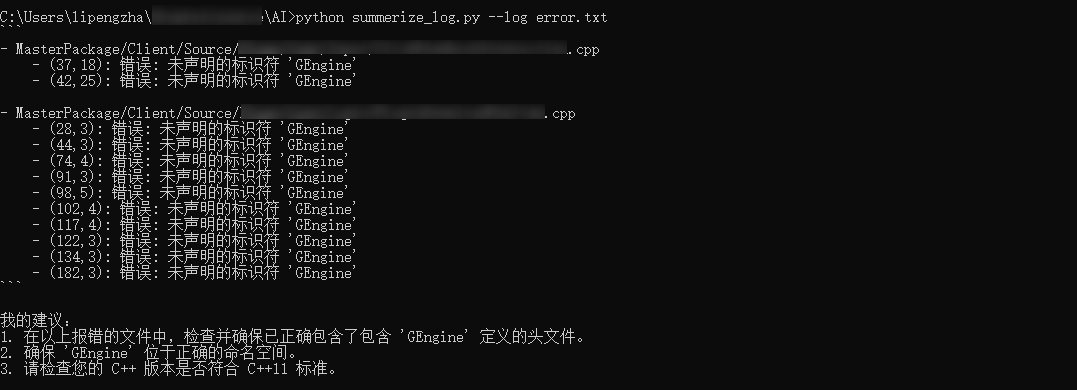
int iArry[10] = {0}; for(int index = 0;index <= 10; ++index) { printf("%d",iArry[index]); }
喂给GPT-4的Prompt为:
1 2 3 4 5 6 7 8
Go line-by-line and do a detailed inspection of my code looking for bugs. If you see a bug, identify it. Explain what the bug is and provide a fix. Respond using Chinese and as a well-formatted markdown file that is organized into sections.Make sure to use code blocks. Inspect this code: int iArry[10] = {0}; for(int index = 0;index <= 10; ++index) { printf("%d",iArry[index]); }
GPT的输出:
问题1:数组越界 问题描述 在给定的循环中,遍历的次数应该小于数组长度。当前的条件是 index <= 10,数组长度为10,循环将会访问数组的第11个元素,导致数组越界。
解决方案 将循环条件改为 index < 10:
1 2 3 4 5 6
int iArry[10] = {0};
for(int index = 0; index < 10; ++index) { printf("%d", iArry[index]); }
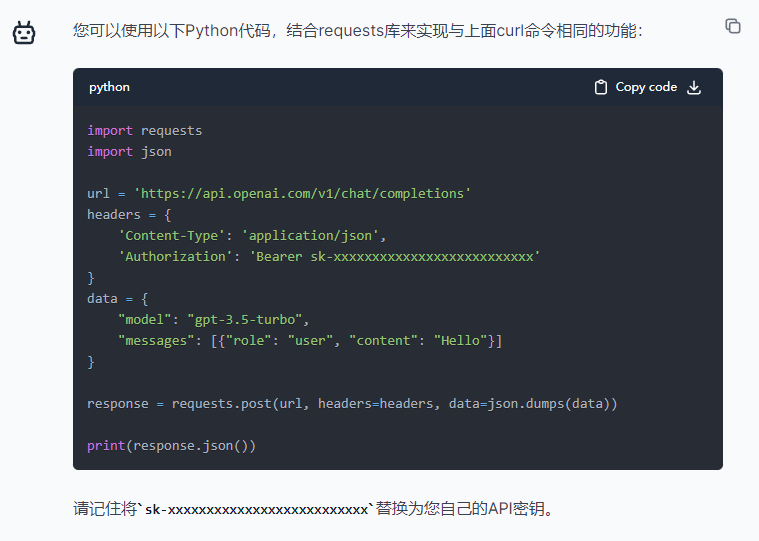
reads the visible text in the image and outputs it as structured JSON data.
features
Caption
describes the image content with a complete sentence in supported languages.
features
DenseCaption
generates detailed captions for individual regions in the image.
features
SmartCrops
finds the rectangle coordinates that would crop the image to a desired aspect ratio while preserving the area of interest.
features
Objects
detects various objects within an image, including the approximate location. The Objects argument is only available in English.
features
Tags
tags the image with a detailed list of words related to the image content.
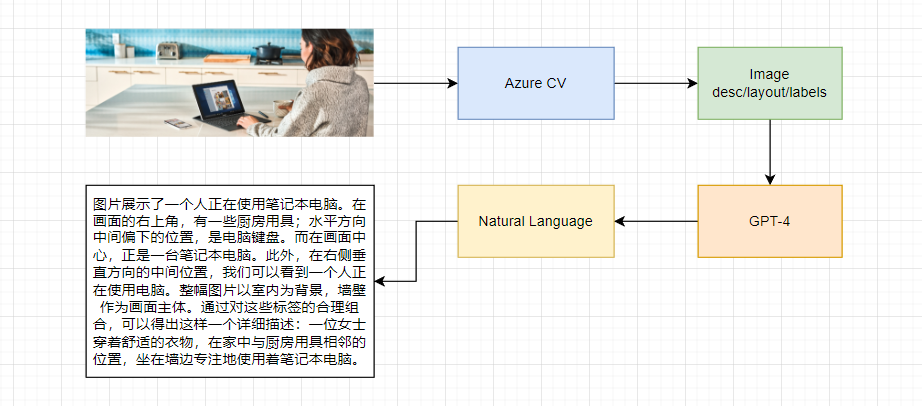
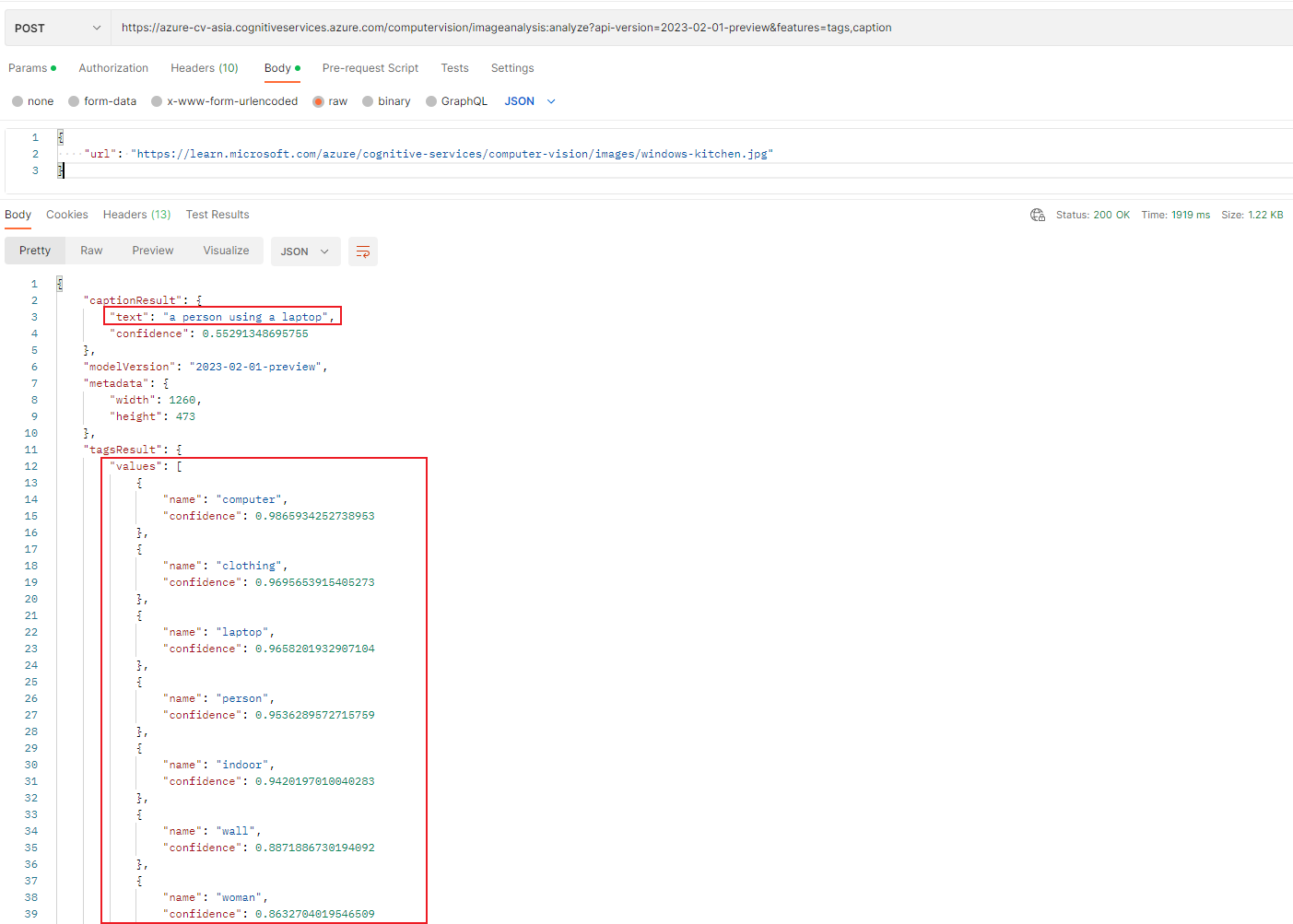
通过分析POST请求的结果,就能得到图片描述和画面中的元素信息(标签、位置):
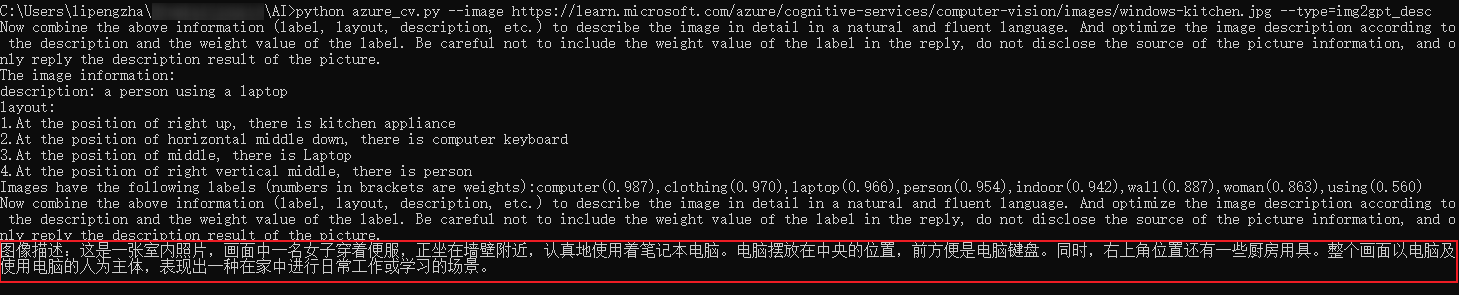
通过解析这个结果,给GPT-4生成一份图像描述的Prompt:
1 2 3 4 5 6 7
description: a person using a laptop layout: 1.At the position of right up, there is kitchen appliance 2.At the position of horizontal middle down, there is computer keyboard 3.At the position of middle, there is Laptop 4.At the position of right vertical middle, there is person Images have the following labels (numbers in brackets are weights):computer(0.987),clothing(0.970),laptop(0.966),person(0.954),indoor(0.942),wall(0.887),woman(0.863),using(0.560)
Go line-by-line and do a detailed inspection of my code looking for bugs. If you see a bug, identify it. Explain what the bug is and provide a fix. Respond using Chinese and as a well-formatted markdown file that is organized into sections.Make sure to use code blocks. Inspect this code: {{code}}
改进代码 改进给定的代码。
1 2 3 4 5
Improve the given code. Don't change any core functionality. The focus is to actually make the code better - not to explain it - so avoid things like just adding comments to it. Respond using Chinese and as a well-formatted markdown file that is organized into sections. Make sure to use code blocks. Improve this code: {{code}}
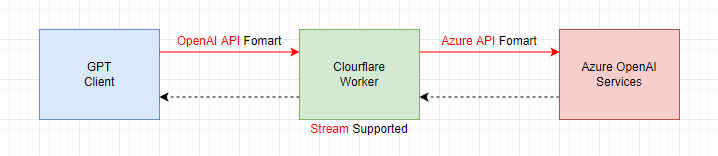
// The name of your Azure OpenAI Resource. const resourceName=""
// The deployment name you chose when you deployed the model. // const deployName="deployment-name" // The mapping of model name. const mapper = { 'gpt-3.5-turbo': 'gpt-35-turbo', 'gpt-4': 'gpt-4', 'gpt-4-32k': 'gpt-4-32k', 'text-embedding-ada-002': 'text-embedding-ada-002' // Other mapping rules can be added here. }; const apiVersion="2023-03-15-preview"
let buffer = ""; while (true) { let { value, done } = await reader.read(); if (done) { break; } buffer += decoder.decode(value, { stream: true }); // stream: true is important here,fix the bug of incomplete line let lines = buffer.split(delimiter);
// Loop through all but the last line, which may be incomplete. for (let i = 0; i < lines.length - 1; i++) { await writer.write(encoder.encode(lines[i] + delimiter)); awaitsleep(30); }