- C/C++标准的一些摘录
- C/C++中的编程技巧及其概念
- Cpp Core Guidelines
- In-depth: Functional programming in C++
- 在拥挤和变化的世界中茁壮成长:C++ 2006–2020
using别名用在friend的错误
C++标准要求friend声明中的类型必须是类或函数,而不能是using别名。
1 | // 错误代码 |
只能让friend是一个具体的类:
1 | class SomeClass; |
Clang编译C++为WebAssembly
1 | llc --version | grep wasm |
LLVM自带IR解释器
lli:
1 | lli test.ll |
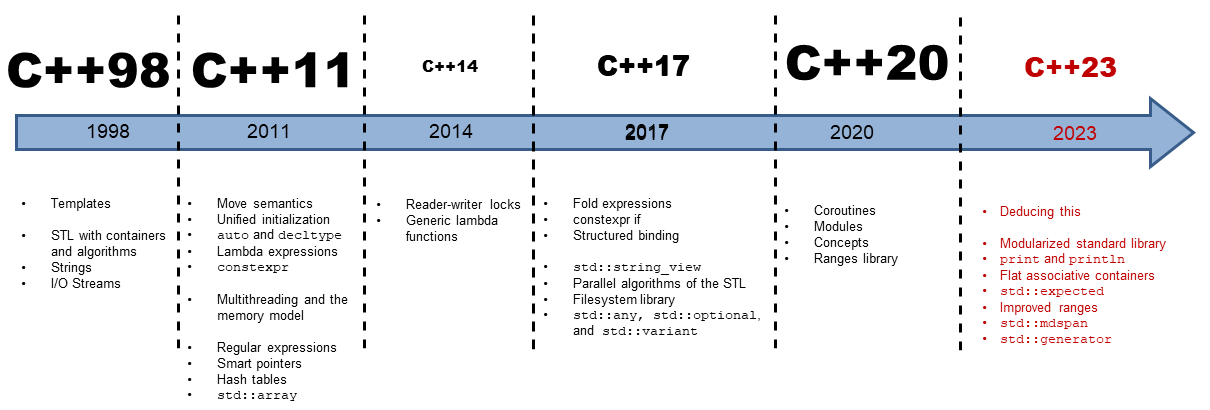
C++23:The Next C++ Standard
MinGW-w64的Win独立构建
可以在这里下载,并且直接包含了Clang:WinLibs standalone build of GCC and MinGW-w64 for Windows
[[nodiscard]]
[[nodiscard]] 是 C++17 引入的属性(attribute),用于告诉编译器一个函数的返回值应该被使用,如果返回值被忽略了,编译器会产生警告。
在使用 [[nodiscard]] 属性声明的函数中,如果函数的返回值没有被用到,编译器会发出警告,以提醒开发者检查代码逻辑。这样可以帮助开发者发现潜在的错误和漏洞,并改善代码的可维护性。
使用 [[nodiscard]] 属性可以帮助开发者避免一些常见的错误,例如:
- 漏掉错误检查
- 错误使用返回值
- 未处理函数的返回值
下面是一个使用 [[nodiscard]] 属性的示例:
[[nodiscard]] int myFunction();
在这个示例中,myFunction() 函数使用 [[nodiscard]] 属性声明其返回值应该被使用。如果开发者没有使用该函数的返回值,编译器会发出警告,以提醒开发者检查代码是否正确。
需要注意的是,[[nodiscard]] 属性只适用于函数的返回值,不能用于变量或其他类型的表达式。

C99 VAL are turing complete
禁用特定编号的警告
1 |
|
构造函数为什么不能取地址?
C++中有指向成员指针的操作,可以用来获取指向数据成员或者成员函数的指针:
1 | struct A |
但是C++标准中有说,不能对构造函数取地址,这是为什么呢?
因为构造函数没有返回值所以不能用函数指针的写法吗?其实不是的,编译器在编译时会给构造函数生成一个函数,以LLVM-IR为例:
1 | ; Function Attrs: nounwind uwtable |
和普通的函数是一样的。
但是,构造函数有一些特殊的性质:
- 语法层面无返回值
- 对象在执行构造函数之前处于一种不完备状态
我猜测是,因为执行构造之前对象只是一段混沌的内存,所以它需要初始化关键的信息:构造基类子对象/多态实现等。
模板特化的类型萃取
在UE中的TStructOpsTypeTraits模板就是通过这种方式来萃取每个类型的标记。
1 | template<class TYPE_NAME> |
友元关系不能被继承
在[ISO/IEC 14882:2014]中标准有描述,友元关系不能被继承也不能被传递:
Friendship is neither inherited nor transitive.
1 | class A { |
Scoped enum
C++11引入了scoped enum:
1 | enum class EClassEnum{ |
为什么要引入这么语法呢?因为C++11之前的enum,其枚举值得定义是位于整个所属名字空间的。C++标准中的描述:
[IOS/IEC 14882:2014 §7.2]The enumeration type declared with an enum-key of only enum is an unscoped enumeration, and its enumerators are unscoped enumerators.
下面代码就会出现重定义错误:
1 | enum ENormalEnum{ |
所以在一般写代码时会加上namespace来区分:
1 | namespace ENamespaceEnum |
因为上面Type的枚举值是位于当前namespace的,所以就可以以下面这种形式来使用:
1 | ENamespaceEnum::A; |
这其实是一种弱类型枚举,枚举本身并不是一个类型。所以C++11引入了Scoped Enum,可以理解为强类型枚举:
1 | enum class EScopedEnum{ |
使用它可以具有与上面namespace形式一样的效果。
Scoped Enumeration的值也是可以显式转换为数值类型的:
[IOS/IEC 14882:2014 §5.2.9]A value of a scoped enumeration type (7.2) can be explicitly converted to an integral type.
而且,如果scoped enum的基础类型没有被显式指定的话,它的默认基础类型是int:
[IOS/IEC 14882:2014 §7.2]Each enumeration also has an underlying type. The underlying type can be explicitly specified using enum-base; if not explicitly specified, the underlying type of a scoped enumeration type is int.
在LLVM中,对Scoped enum的处理是在编译器前端做的,下列代码生成的IR代码:
1 | enum ENormalEnum{ |
main函数的LLVM-IR:
1 | ; Function Attrs: uwtable |
在生成IR时就没有符号信息,只剩常量了。
LoadLibrary faild
GetLastError获取错误代码:
- 126:依赖的DLL找不到。
- 127 :DLL找到了,但是DLL里需要的符号找不到,通常就是版本有问题。
- 193:无效的DLL文件,请检查DLL文件是否正常以及x86/x64是否匹配。
预处理使用##时需要注意编译器的不统一
下列代码在MSVC中编译的过:
1 |
|
但是在GCC/Clang中会又如下错误:
1 | Preprocess.cpp:16:1: error: pasting formed ',FString', an invalid preprocessing token |
这是由于GCC/Clang要求预处理之后的的结果必须是一个已定义的符号,MSVC在这方面和它们不一样,解决办法为在非拼接顺序字符的地方删掉##:
1 |
相关文章:
- Pasting formed an invalid processing token ‘.’
- Error: Pasting formed with invalid preprocessing token
C++中delete[]的实现
注意:不同的编译器实现可能不一样,我使用的是Clang 7.0.0 x86_64-w64-windows-gnu
在C++中我们可以通过new和new[]在堆上分配内存,但是有没有考虑过下面这样的问题:
1 | class IntClass{ |
因为i就只是一个普通的指针,所以它没有任何的类型信息,那么delete[]的时候怎么知道要回收多少内存呢?
所以肯定是哪里存储了i的长度信息!祭出我们的IR代码:
1 | ; Function Attrs: noinline norecurse optnone uwtable |
可以看到编译器给我们的new IntClass[10]通过@_Znay(i64 48)来分配了48个字节的内存!
但是按照sizeof(IntClass)*10来算其实之应该有40个字节的内存,多余的8个字节用来存储了数组的长度信息。
1 | %3 = call i8* @_Znay(i64 48) #8 |
可以看到,它把数组的长度写入到了分配内存的前8个字节,在八个字节之后才可以分配真正的对象。
我们真正得到的i的地址就是偏移之后的,数组的长度写在第一个元素之前的64位内存中。
1 | // 每个x代表一个byte,new IntClass[10]产生的内存布局 |
既然知道了它存在哪里,所以我们可以修改它(在修改之前我们delete[] i;会调用10次析构函数):
1 | IntClass *i = new IntClass[10]; |
这样修改之后delete[] i;只会调用1次析构函数,也印证了我们猜想。
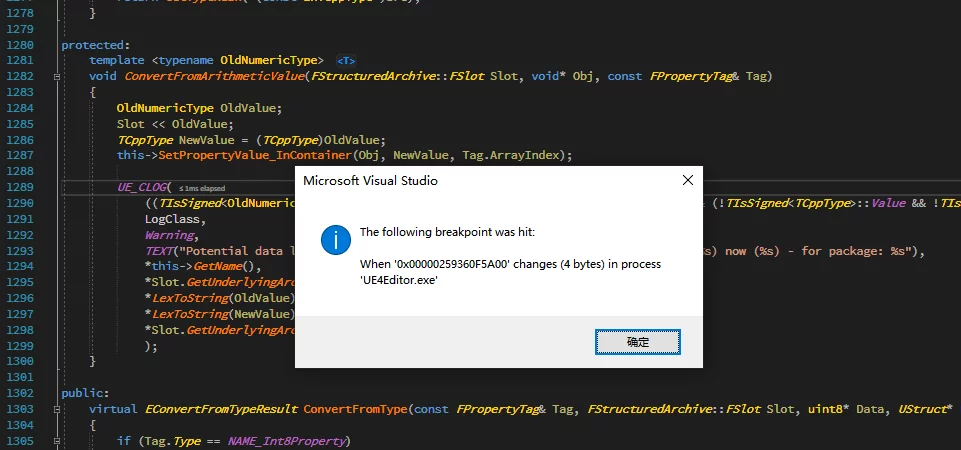
VS内存断点
在使用VS调试的时候有在有些情况下需要知道一些对象在什么时候被修改了,如果按照单步一点一点来调试的话很不方便,这时候就可以使用VS的Data Breakpoint来进行断点调试:
添加Data Breakpoint的操作为Debug-New BreakPoint-Data Breakpoint(或者在Breakpoint窗口下):
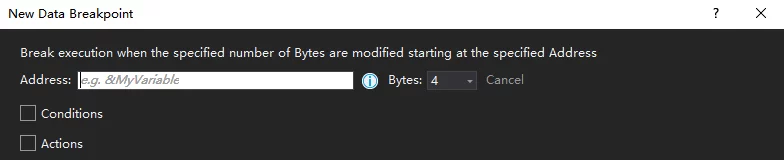
需要在Address处输入要断点的内存地址,可以输入对象名字使用取地址表达式(&Test),如果想要断点的对象不是全局对象可以通过直接输入内存地址。
获取一个对象的内存地址的方法为在Watch下添加一条该对象的取地址表达式(可以使用&ival或者&this->ival):
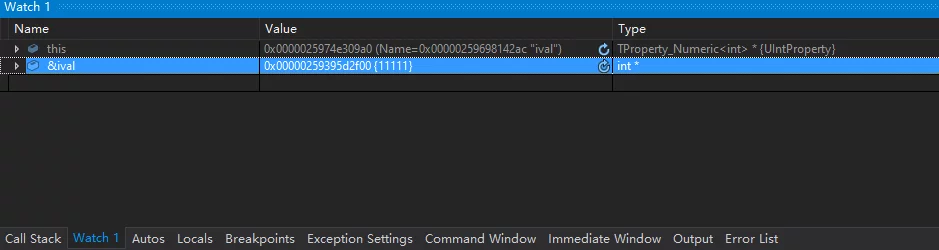
其中Value的就得到了该对象的内存地址。
拿到内存地址之后就可以填到Data Breakpoint的Address中了,然后指定它的数据大小(可选1/2/4/8):
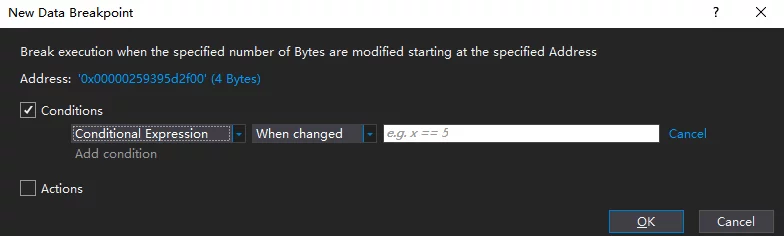
当该地址的数据被修改时会提示触发了内存断点:
move和forward的区别
std::move和std::forward均是定义在<utility>中的函数。
| function | describle |
|---|---|
| x2=forward(x) | x2是一个右值,x不能是左值;不抛出异常 |
| x2=move(x) | x2是一个右值;不抛出异常 |
| x2=move_if_noecept(x) | 若x2可移动,x2=move(x);否则x2=x;不抛出异常 |
std::move进行简单的右值转换:
1 | template<typename T> |
其实move应该命名为rvalue才对,它没有移动任何东西,而是从实参生成一个rvalue,从而所指向的对象可以移动。
我们用move告知编译器,此对象在上下文中不再被使用,因此其值可以被移动,留下一个空对象。最简单的就是swap的实现。
std::forward从右值生成一个右值:
1 | template<typename T> |
这对forward函数总是会一直提供,两者间的选择是通过重载解析实现的。任何左值都会由第一个版本处理,任何右值都会有第二个版本处理。
1 | int i=7; |
第二个版本的断言是为了防止用显示模板实参和一个左值调用第二个版本。
forward的典型用法是将一个实参完美转发到另一个函数。
当系统用移动操作窃取一个对象的表示形式时,使用move;当希望转发一个对象时,使用forward。因此forward总是安全的,而move标记x将被销毁,因此使用时要小心。调用std::move(x)之后x唯一的用法就是析构或者赋值目的。
rvalue和lvalue的重载规则
实现non-const lvalue版本
如果一个类只实现了:
1 | A(A&){} |
则该类只能被lvalue调用,但不能被rvalue调用。如下列代码:
1 | class A{ |
会有下列错误:
1 | C:\Users\visionsmile\Desktop\cpp\rvalue.cpp:31:4: error: no matching constructor for initialization of 'A' |
实现const lvalue版本
如果实现了const版本:
1 | A(const A& In){printf("A(const A& In);\n");} |
则既可以被rvalue也可以被lvalue调用。
只实现rvalue版本
如果类中只有rvalue的函数版本:
1 | A(A&& rIn){printf("A(A&& rIn);\n");} |
则只能被rvalue调用,不能被lvalue调用。
1 | class A{ |
或有下列编译错误:
1 | C:\Users\visionsmile\Desktop\cpp\rvalue.cpp:31:4: error: call to implicitly-deleted copy constructor of 'A' |
既有rvalue也有lvalue版本
如果既提供了rvalue也提供了lvalue版本,则可以区分为rvalue服务和为lvalue服务的能力
1 | class A{ |
结语
如果类未提供move语义,只提供常规的copy构造函数和copy assignment操作符,rvalue引用可以调用他们。
因此std::move意味着:调用move语义,否则调用cop语义。
rvalue和lvalue
rvalue(左值)是指对象的一条表达式,左值的字面意思是能再赋值运算符左侧的东西。但其实不是所有的左值都能用在赋值运算符的左侧,左值也有可能指示某个常量。
待补充。
C++局部对象的销毁顺序
C++标准规定按照构造的逆序执行销毁。
[ISO/IEC 14882:2014 § 6.6]On exit from a scope (however accomplished), objects with automatic storage duration (3.7.3) that have been constructed in that scope are destroyed in the reverse order of their construction.
C++函数的后置&与&&修饰符
考虑下面例子代码:
1 | template<typename T> |
这个A::Get函数后面的&与&&修饰符是什么作用呢?
其实主要是因为这两个函数的原型只有返回值类型不同,但是,类成员函数的签名不包含返回值类型,所以他们会又重定义错误,而加这两个修饰的目的是让他们的签名不同。
C++类成员函数的签名组成:
- name
- parameter type list
- class of witch the function is a member
- cv-qualifiers(if any)
- ref-qualifer(if any)
声明部分的语法描述在**[IOS/IEC 14882:2014 § 8 Declarators]**
static的链接问题
在global/namespace scope的static函数/变量,仅在定义它的**翻译单元(translation unit)**可用,在其他的翻译单元不可用。
如有三个文件:
1 | // file.h |
1 | // file.cpp |
1 | // main.cpp |
使用下列命令编译:
1 | # 注意此处有两个翻译单元 main.cpp/file.cpp |
会产生链接错误:
1 | In file included from main.cpp:2: |
这是因为func是个static函数,而且定义在file.cpp的翻译单元,因为static对象的internal linkage性质,而main.cpp的翻译单元不包含func的定义,所以会产生上面的链接错误。
知道了原因,那么解决办法有两个:
- 去掉
func的static; - 在所有用到
func的翻译单元中包含func的定义。
placement-new编译时的错误
1 | 'operator new' : function does not take 2 arguments |
这个错误是因为没有包含new.h/new.
The Next Big Thing:C++20
这篇文章简单介绍了C++标准的历史和新标准的动向。
变量已被优化,因而不可用
在VS调试中,有时候会在Debug窗口看到变量已被优化,因而不可用,导致看不到对象值。可以在VS的项目设置中关闭优化。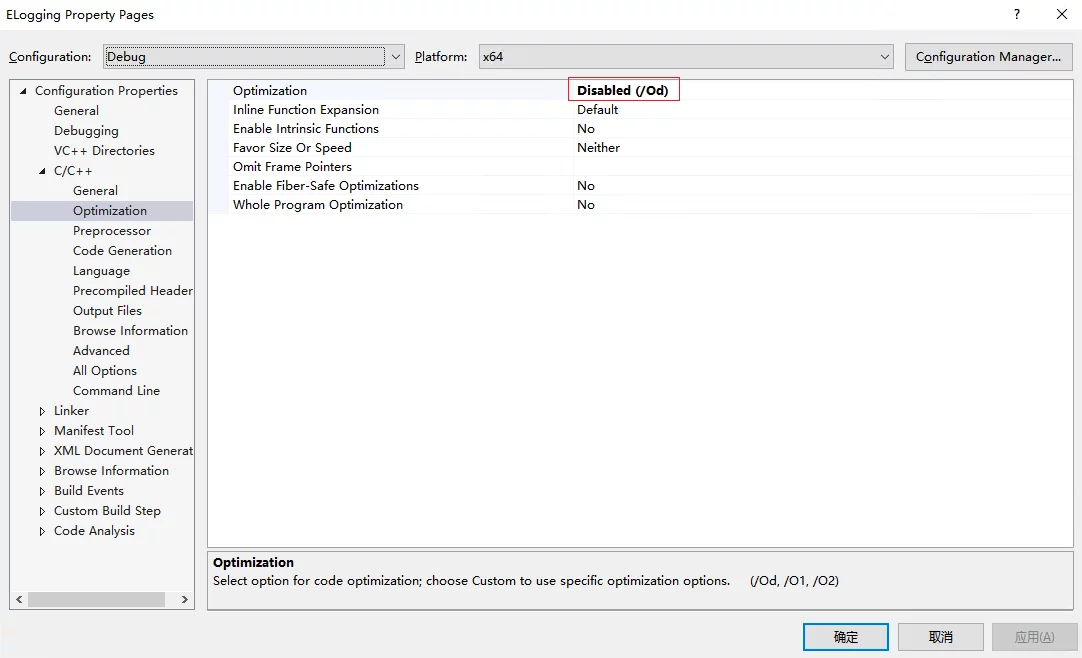
C5083错误
1 | error C5038: data member 'UTcpNetPeer::ConnectionState' will be initialized after data member 'UTcpNetPeer::OpenedTime' |
其实这个应该不算做错误,只是UE 4.22的警告等级比较高。
这个报错的意思是,在构造函数的定义里对数据成员的初始化的顺序与在声明中不一样,建议还是改掉,但是如果改动量太多,可以禁用掉C5083这个警告。
1 |
VS中的属性宏
在VS中配置include或者链接lib的时候需要指定路径,但是绝对路径很方便,可以使用VS的属性宏来设置。
比较常用的有以下几个:
SolutionDir:解决方案的路径。ProjectDir:项目的路径。ProjectName:项目名。Platform:平台(x86/x64等)Configuration:配置(Debug/Release)RuntimeLibrary:运行时的类型MT/MD- 也可以包含用户自己在系统中的创建的环境变量,如
$(BOOST)等。
用法皆是$(VAR_NAME),如$(SolutionDir)。
微软有个页面列出了VS中可用的属性宏:Common macros for MSBuild commands and properties
在VS中也可以通过Project Properties-Configuration Properties-C/C++-General-EditAdditional Include Direcories-Macro中找到支持的宏列表: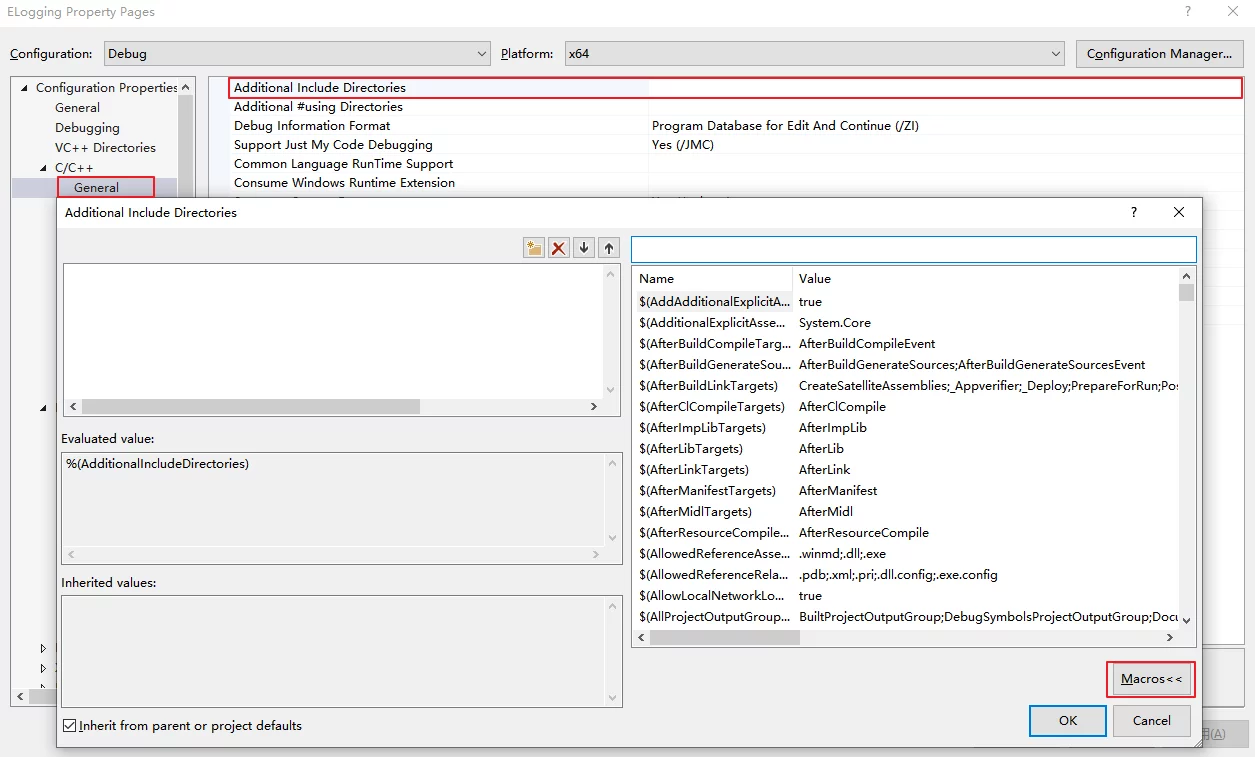
使用Win库但没有添加链接库的链接错误
在代码中使用了MessageBoxA,但是在链接时却产生了一个链接错误:
1 | 1>------ Build started: Project: ELogging, Configuration: Debug x64 ------ |
说的是在WriteMsgs中使用到的符号__imp_MessageBoxA没有定义。
这个符号是定义在user32.lib中的,在项目中添加上即可,原本以为win库的lib都是默认链接的,坑。
相关问题:junk.obj : error LNK2019: unresolved external symbol __imp_MessageBoxA referenced in function main
引入外部Lib时的LINK1112链接错误
1 | libboost_thread-vc140-mt-gd-1_62.lib(thread.obj) : fatal error LNK1112: module machine type 'x86' conflicts with target machine type 'x64' |
该错误表示,当前编译的项目的目标机器是x64,但是项目中引用的libboost_thread-vc140-mt-gd-1_62.lib却是x86的,所以才会报这个错误。
引入外部Lib时的LINK2038链接错误
1 | 2>Generating Code... |
这个错误的关键点在于,当前的项目编译的Runtime Library的类型是MTd_StaticDebug而依赖的链接库libboost_thread-vc140-mt-gd-1_62.lib是MDd_DynamicDebug,所以造成了链接时的不匹配:
1 | error LNK2038: mismatch detected for 'RuntimeLibrary': value 'MDd_DynamicDebug' doesn't match value 'MTd_StaticDebug' in ELogging.obj |
知道了问题,那么解决这个问题的办法就是,使当前编译的项目的RuntimeLibrary类型和所有依赖的lib的RuntimeLibrary类型保持一致。
修改方法为:Project Properties-Configuration-C/C++-Code Generation-Runtime Library:

这是个坑点,在引入外部的Lib的时候一定要看清楚项目所依赖的类型。
预编译的C1010错误
编译代码时在一个全部代码全部被注释的.cpp文件中报了下面一个错误:
1 | fatal error C1010: unexpected end of file while looking for precompiled header. Did you forget to add '#include "stdafx.h"' to your source? |
提示没有添加预编译头stdafx.h到文件,可以报错的文件包含即可,但是这里我又不需要让它包含。
那么可以进入Project Properties-C/C++-Precompiled Header,将Precompiled Header改为Not Using Precompiled Headers,重新编译即可,缺点就是不能使用预编译的加速了。
所谓头文件预编译,就是把一个工程(Project)中使用的一些标准头文件(如Windows.h、Afxwin.h)预先编译,以后该工程编译时,不再编译这部分头文件,仅仅使用预编译的结果。这样可以加快编译速度,节省时间。
预编译头文件通过编译stdafx.cpp生成,以工程名命名,由于预编译的头文件的后缀是pch,所以编译结果文件是ProjectName.pch。
编译器通过一个头文件stdafx.h来使用预编译头文件。stdafx.h这个头文件名是可以在project的编译设置里指定的(Project Properties-C/C++-Precompiled Header-Precompiled Header File)。
编译器认为,所有在指令#include "stdafx.h"前的代码都是预编译的,它跳过#include "stdafx.h"指令,使用ProjectName.pch编译这条指令之后的所有代码。 因此,所有的CPP实现文件第一条语句都是#include "stdafx.h"。
类内默认值与构造函数初始化的顺序
在C++11中,引入了类内初始化机制:
1 | class A{ |
但是这又会引入一个问题:如果我同时使用类内初始化和构造函数初始化两种方式,那么真正使用的又是什么呢?
1 | class A{ |
上面的代码ival的值应该是多少呢?
这一点在C++标准中给了明确的解答:
[IOS/IEC 14882:2014 §12.6.2.9]If a given non-static data member has both a brace-or-equal-initializer and a mem-initializer, the initialization specified by the mem-initializer is performed, and the non-static data member’s brace-or-equal-initializer is ignored.
1 | struct A { |
the A(int) constructor will simply initialize i to the value of arg, and the side effects in i’s brace-or-equal-initializer will not take place.
但是我仍想自己分析一下编译器的实际处理,在之前的文章和笔记中,已经知道了编译器会将类内初始化的操作合并到构造函数中,其执行是在基类的构造之后,自己的构造函数体之前。依然使用LLVM-IR代码分析:
1 | class A{ |
其构造函数的IR代码为:
1 | ; Function Attrs: noinline optnone uwtable |
可以看到,是先初始化了this指针,然后根据this指针获取到成员ival,然后对其进行初始化(IR里的store操作)。
如果我们使用构造函数初始化的写法呢?
1 | class A{ |
真正的行为为:ival被初始化为11。
其IR代码为:
1 | ; Function Attrs: noinline optnone uwtable |
通过diff发现,两个版本的IR代码唯一区别就是初始数值不一样,其他的逻辑都是一模一样的:
变量模板的特化
求和:
1 | template <int EndPoint> |
斐波那契第N项:
1 | template <int EndPoint> |
最大支持的参数取决于编译器的最大递归深度,Clang可以通过-ftemplate-depth=N来指定。
note: use -ftemplate-depth=N to increase recursive template instantiation depth
What is the Object in C/C++?
首先先说C++中的**对象(object)**:
在一些教材中,会刻意渲染C++中的对象就是面向对象(object-oriented),这里的对象是类对象(class Object),但是C++标准规定的Object并不是这么狭隘的概念,C++里占用存储空间即对象(函数除外。
**[ISO/IEC 14882:2014 §1.8]**An object is a region of storage. [ Note: A function is not an object, regardless of whether or not it occupies storage in the way that objects do.——end note ] An object is created by a definition (3.1), by a new-expression (5.3.4) or by the implementation (12.2) when needed.
有些人说C++里只有class object是对象,这是很狭隘的观点,如果只有class object才能叫对象,那么该怎么描述built-in type的实例?而且class本身也就是要提供和built-in type相同的操作方式,类型的实体统一叫做**对象(Object)**才是恰当的。
**[ISO/IEC 14882:2014 §1.8]**An object can have a name (Clause 3). An object has a storage duration (3.7) which influences its lifetime (3.8). An object has a type (3.9). The term object type refers to the type with which the object is created.
如果从面向对象(object-oriented)理论的封装、继承和多态这个角度来说,确实只有class object是这个语境下的对象,不过C++标准的对象模型是存储及对象(An object is a region of storage)。
C语言中的对象(object)**概念与C++中类似,也是存储即对象**:
[ISO/IEC 9899:1999 §3.14]region of data storage in the execution environment, the contents of which can represent values
C++模板必须提供声明和定义的原因
因为在C++中使用模板会产生新的类型,而只有在当前使用模板的翻译单元会产生(因为编译器只会推导当前翻译单元的模板)。如果模板和声明和定义分离,使用模板时产生了一个符号(类型),则编译器就会去查找该符号的定义,那么问题来了,如果模板的定义在其他的翻译单元,编译器的手伸不到,怎么在一个翻译单元产生一个符号的声明,而让另一个翻译单元也同样产生一个相同符号的定义呢?是因为编译器直到使用模板的确切地点才能
知道用哪些模板实参来实例化它。结果就是会产生链接错误。
所以,模板必须要同时提供声明和定义,才会使模板推导出的符号声明和定义会一致生成(把模板当成内联代码更容易理解)。
C++历史上(C++03)曾经允许过模板的分离编译(使用export),但是这个特性在C++11之后就废除掉了,一是其局限性太大(并不像普通的提供声明-定义的分离式编译那样,编译时仍需要提供代码的实现),二是其太难实现了(只有一个编译器Comeau实现过)。
VS修改文件编码
选择Tools-Customize-Commands: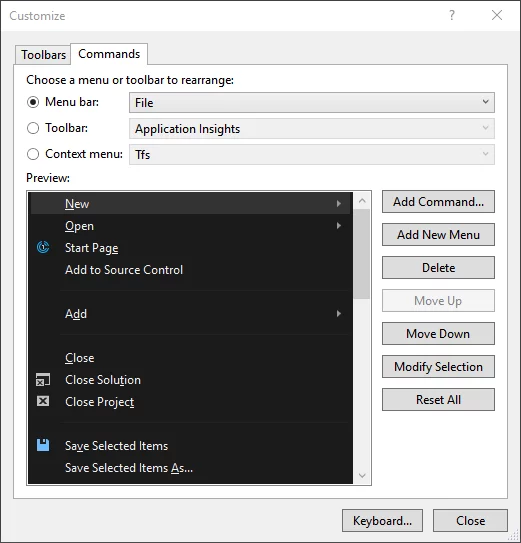
在File下添加Advanced Save Options选项: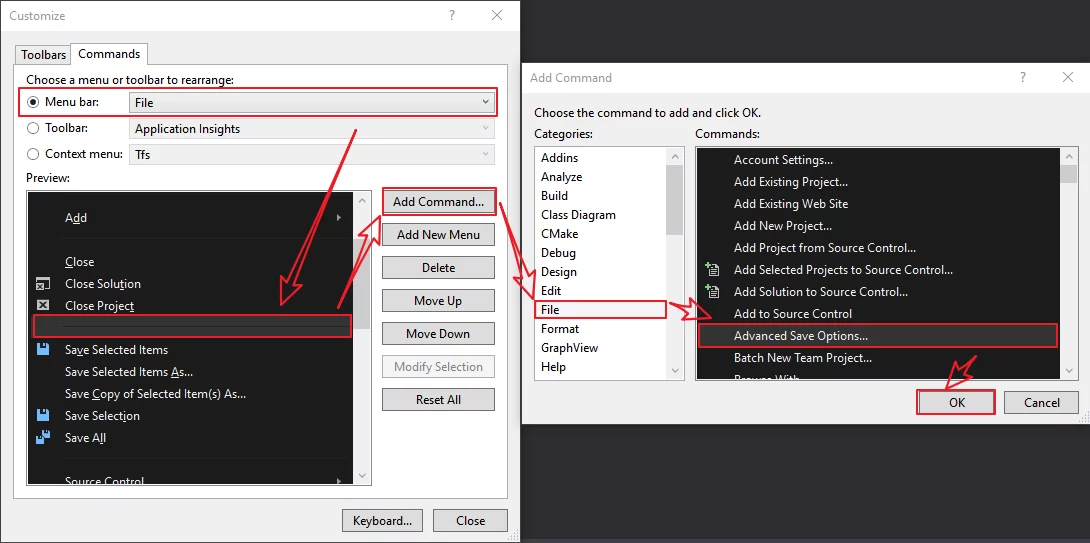
然后打开文本文件时就可以在VS的菜单File下看到Advanced Save Options选项了: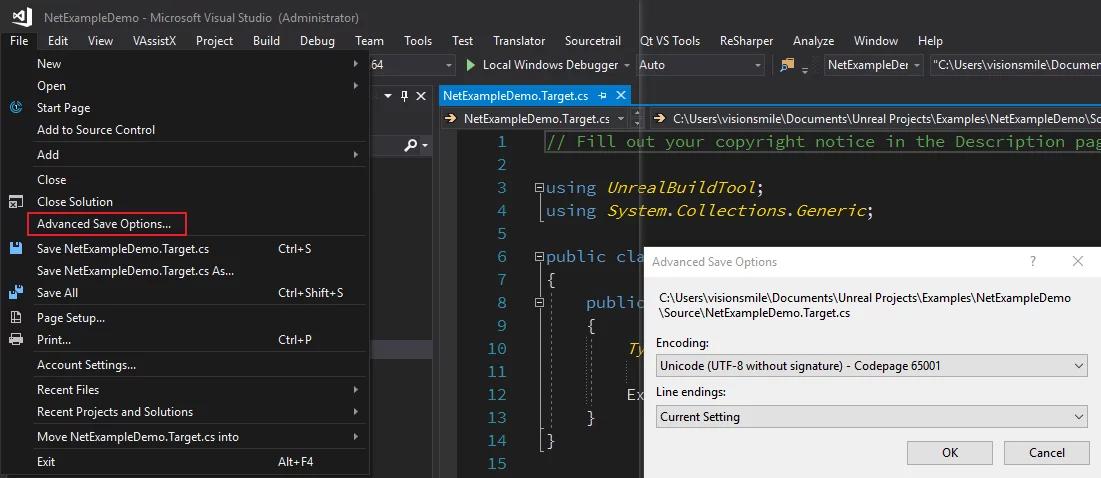
或者安装插件ForceUTF8(NoBOM)
PS:最好代码都使用Unicode编码,避免编码问题造成奇奇怪怪的编译错误。
C++模板特化实例的static成员
每个从模板类特化出的类模板特化实例都具有自己单独的static成员:
1 | template <typename T> |
[ISO/IEC 14882:2014 § 14.7]Each class template specialization instantiated from a template has its own copy of any static members.
this不能用在函数默认参数的原因
注意:成员函数(this传递)实现是Implementation-define的。
在我之前的文章中写道过,C++的成员函数与普通的函数之间的区别是具有隐式的this指针:
1 | void func(){} |
他们的区别是:
1 | // ::func |
本质上来说,成员函数的调用就是将当前对象的地址作为实参传递给函数形参this。
之所以不能够在成员函数的默认实参使用this则因为,在C++中函数参数的求值顺序是不一定的:
[ISO/IEC 14882:2014 §8.3.6.9]A default argument is evaluated each time the function is called with no argument for the corresponding parameter. The order of evaluation of function arguments is unspecified. Consequently, parameters of a function shall not be used in a default argument, even if they are not evaluated. Parameters of a function declared before a default argument are in scope and can hide namespace and class member names.
1 | int a; |
因为上面的分析我们已经知道了,this指针实际就是函数的形参,所以如果允许this作为函数形参的默认参数,则:
1 | class A{ |
这样的写法就是一个形参的默认实参依赖于另一个形参,因为函数形参的传递是没有顺序的,所以不能在默认参数中使用this.
标准的规则是相通的,一个规则适用在这里,必然也会在另一个地方也会受到限制。
萃取数组的元素个数
1 |
|
Bin2Hex
我写了一个小工具,把二进制文件转换为hex数据的,思路就是对二进制文件逐字节地读取然后写入一个字符串中:
下载bin2hex,用法如下:
1 | # bin2hex.exe FileName |
会在当前目录下产生一个Icon_ico.h文件,记录着Icon.ico的二进制数据:
1 | // Icon_ico.h |
在使用的时候,将这个字符数组内的数据以二进制模式写入文件即可恢复源文件(逐字节地写入文件):
1 | // hex2bin.cpp |
这种方式在写Console程序时,编译进去一些资源很有用。
C读写二进制文件
读:
1 | FILE* fp=fopen(rFileName, "rb"); |
写:
1 | static const unsigned char |
GNU扩展:struct初始化[first … last]
GNU的扩展支持以下这样一种结构初始化的写法(Designated-Inits):
1 |
|
这段代码的意思是对DataList内的所有元素的ival成员初始化为2.
1 |
|
虽然说也可以使用一个循环赋值来实现:
1 |
|
但是比较二者的汇编代码:
1 | ############################### |
1 | ############################### |
可以看到,直接初始化的效率更高,不过从“可读性”(毕竟它不是标准C)和“可移植”的角度看,还是写个循环赋值靠谱一点。
static成员初始化可以访问private成员
C++的static成员初始化是可以访问类的私有成员的:
1 | class process { |
[ISO/IEC 14882:2014 §9.4.2]The static data member run_chain of class process is defined in global scope; the notation process ::run_chain specifies that the member run_chain is a member of class process and in the scope of class process. In the static data member definition, the initializer expression refers to the static data member running of class process. — end example ]
!!的用法
看到!的这样一个用法:
1 | int main() |
作用是如果ival是0,则!!ival的值是0,ival非0,则结果为1.
以下是两份代码的IR对比:
1 | // cpp |
使用!!的代码:
1 | // cpp |
C语言中的枚举就是整型
**[ISO/IEC 9899:1999 §6.4.4.4.2]**An identifier declared as an enumeration constant has type int.
**[ISO/IEC 9899:1999 §6.7.2.2.3]**The identifiers in an enumerator list are declared as constants that have type int and may appear wherever such are permitted.
注:C++与C不同,C++的枚举是单独的类型,详见[ISO/IEC 14882:2014 C.16 Clause7]。
C++中纯虚函数不能够提供定义
**[ISO/IEC 14882:2014 §10.4]**A function declaration cannot provide both a pure-specifier and a definition.
1 | struct C { |
正则匹配C函数声明
1 | ^([\w\*]+( )*?){2,}\(([^!@#$+%^;]+?)\)(?!\s*;) |
来源:Regex to pull out C function prototype declarations?
C语言中聚合结构的初始化
C语言的聚合结构还有这种方式的初始化:
1 | struct { int a;float b; } x ={ .a = 2,.b = 2.2 }; |
这是因为inielizer的designator可以是[constant-expression]和.identifier.
PS:sizeof(w) == ?是个有趣的问题。
详情请看**[ISO/IEC 9899:1999 §6.7.8]**.
通过函数指针进行函数调用不可以使用默认参数
如题:
1 | void func(int ival=123) |
先来看一下函数的默认参数是在何时被填充上去的,老样子还是看LLVM-IR代码:
1 | void func(int ival=123) |
其main函数的LLVM-IR代码为:
1 | define dso_local i32 @main() #6 { |
可以看到在编译时通过代码分析直接把省略掉的参数用默认值给补上了。
函数指针只具有函数的地址值,不包含任何的实参信息,也就不能在函数指针的访问里使用默认参数咯。
注:成员函数指针也同理。
unspecified behavior
behavior, for a well-formed program construct and correct data, that depends on the implementation.[ Note: The implementation is not required to document which behavior occurs. The range of possible behaviors is usually delineated by this International Standard. — end note ]
well-formed program
[ISO/IEC 14882:2014 §1.3.26]C++ program constructed according to the syntax rules, diagnosable semantic rules, and the One Definition
Rule (3.2).
Implementation-Define(实现定义行为)
[ISO/IEC 14882:2014]behavior, for a well-formed program construct and correct data, that depends on the implementation and that each implementation documents
UB(未定义行为)
[ISO/IEC 14882:2014 §1.9.4]This International Standard imposes no requirements on the behavior of programs that contain undefined behavior.
[ISO/IEC 14882:2014 §1.3.24]behavior for which this International Standard imposes no requirements [ Note: Undefined behavior may be expected when this International Standard omits any explicit definition of behavior or when a program uses an erroneous construct or erroneous data. Permissible undefined behavior ranges from ignoring the situation completely with unpredictable results, to behaving during translation or program execution in a documented manner characteristic of the environment (with or without the issuance of a diagnostic message), to terminating a translation or execution (with the issuance of a diagnostic message). Many erroneous program constructs do not engender undefined behavior; they are required to be diagnosed. — end note ]
这意味着具有UB的程序的行为不可预测,什么情况都有可能发生。
关于注入类名字(injected-class-name)的问题
首先要先了解一下什么叫做注入类名字(injected-class-name):
[ISO/IEC 14882:2014(E) §9.0.2]The class-name is also inserted into the scope of the class itself; this is known as the injected-class-name. For purposes of access checking, the injected-class-name is treated as if it were a public member name.
意思就是类的名字被嵌入到类的作用域中,为了访问检查的目的,注入类名称被视为public成员(注意这一句)。
其实对注入类名字的声明类似于下面这样:
1 | class A { |
在类内的名字查找是先从当前作用域开始的,注入类名字被在继承层次中看的更明显一些:
1 | class A{}; |
如上面的代码所示,可以使用B::A来限定B继承层次的类型A.
上面描述的内容中写到,注入类名字被视为public成员,但是如果我们在继承层次中把基类标记为了private,会怎样?
1 | class A { }; |
编译一下代码看一下:
1 | injected-class-name.cpp:4:3: error: 'A' is a private member of 'A' |
那我们使用B::A或者C::A呢?同样也会具有一样的错误。
因为在派生类中对基类名字的名字查找(name lookup)找到的是注入类名字(injected-class-name):
**[ISO/IEC 14882:2014(E) §11.1.5]**In a derived class, the lookup of a base class name will find the injected-class-name instead of the name of the base class in the scope in which it was declared.
要解决这样的问题,要限定名字空间(上面的例子要改为::A):
1 | class A { }; |
注意,在namespace的scope内一定要注意默认的名字查找(name-lookup)是有namespace限定的。
一个要抠字眼的C++问题
问:派生类的对象对他的基类成员中()是可以访问的?
A) 公有继承的公有成员
B) 公有继承的私有成员
C) 公有继承的保护成员
D) 私有继承的公有成员
乍一看,继承层次下的派生类使用public/protected/private都可以访问基类的public/private成员啊,貌似ACD都对。
但是,注意问题里写的是对象,对象只能够访问类的public成员,所以我在问题里加粗了:)。
reintrtpret_cast的转换(位模式的转换)
指针到整型的转换
指针能够显式转换为任何足够容纳它的整型,但是映射函数是实现定义(implementation-define)**的。
类型std::nullptr_t的值能够转换到整型,该转换与转换(void*)0到整型具有相同的意义与合法性。
**注:reinterpret_cast不能用在转换任何类型的值到std::nullptr_t.
*[ISO/IEC 14882:2014 §5.2.10.4]**A pointer can be explicitly converted to any integral type large enough to hold it. The mapping function is implementation-defined. [ Note: It is intended to be unsurprising to those who know the addressing structure of the underlying machine. — end note ] A value of type std::nullptr_t can be converted to an integral type; the conversion has the same meaning and validity as a conversion of (void)0 to the integral type. [ Note: A reinterpret_cast cannot be used to convert a value of any type to the type std::nullptr_t. — end note ]
整型到指针的转换
整型或枚举类型能够显式转换到指针。指针转换到足够大小的整型并且再转换会相同的指针类型,它将会具有源指针值。
这意味着该转换不具有未定义行为(指针与整型之间映射在其他方面是实现定义的):
1 | // 使用c++编译器编译 |
**[ISO/IEC 14882:2014 §5.2.10.5]**A value of integral type or enumeration type can be explicitly converted to a pointer. A pointer converted to an integer of sufficient size (if any such exists on the implementation) and back to the same pointer type will have its original value; mappings between pointers and integers are otherwise implementation-defined. [ Note: Except as described in 3.7.4.3, the result of such a conversion will not be a safely-derived pointer value. — end note ]
函数指针的转换
函数指针能够显示转换到不同类型的函数指针,调用转换后的函数类型的效果与函数定义中的函数不同。
1 | void func(int ival) |
除非转换类型pointer to T1到pointer to T2(T1和T2是函数类型),并且转换回它的源类型产生源指针值,这样的指针转换的结果是未指定的(unspecified).
**[ISO/IEC 14882:2014 §5.2.10.6]**A function pointer can be explicitly converted to a function pointer of a different type. The effect of calling a function through a pointer to a function type (8.3.5) that is not the same as the type used in the definition of the function is undefined. Except that converting a prvalue of type “pointer to T1” to the type “pointer to T2” (where T1 and T2 are function types) and back to its original type yields the original pointer value, the result of such a pointer conversion is unspecified. [ Note: see also 4.10 for more details of pointer conversions. — end note ]
offsetof不能用在非POD类型(Standard Layout)
offsetof是定义在stddef.h/cstddef中的一个宏,其作用是获取结构成员在结构上的偏移。
1 | class A{ |
但是它不能够用在非Standard Layout Class的类型上,否则是undefine behavior的:
[ISO/IEC 14882:2014 §18.2.4]:The macro offsetof(type, member-designator) accepts a restricted set of type arguments in this International Standard. **If type is not a standard-layout class (Clause 9), the results are undefined.**The expression offsetof(type, member-designator) is never type-dependent (14.6.2.2) and it is value-dependent (14.6.2.3) if and only if type is dependent. The result of applying the offsetof macro to a field that is a static data member or a function member is undefined. No operation invoked by the offsetof macro shall throw an exception and noexcept(offsetof(type, member-designator)) shall be true.
Note that offsetof is required to work as specified even if unary operator& is overloaded for any of the types involved.
顺便再来复习一下什么叫Standard Layout types:
[ISO/IEC 14882:2014 §3.9.9]:Scalar types, standard-layout class types (Clause 9), arrays of such types and cv-qualified versions of these types (3.9.3) are collectively called standard-layout types.
而Standard Layout Class则又是:
A standard-layout class is a class that:
- has no non-static data members of type non-standard-layout class (or array of such types) or reference,
- has no virtual functions (10.3) and no virtual base classes (10.1),
- has the same access control (Clause 11) for all non-static data members,
- has no non-standard-layout base classes,
- either has no non-static data members in the most derived class and at most one base class with non-static data members, or has no base classes with non-static data members, and
- has no base classes of the same type as the first non-static data member.
即,在类中有这些的都是非标准布局类,offsetof不能用在他们上面。
C++中的Standard Layout types
顺便再来复习一下什么叫Standard Layout types:
[ISO/IEC 14882:2014 §3.9.9]:Scalar types, standard-layout class types (Clause 9), arrays of such types and cv-qualified versions of these types (3.9.3) are collectively called standard-layout types.
而Standard Layout Class则又是:
A standard-layout class is a class that:
- has no non-static data members of type non-standard-layout class (or array of such types) or reference,
- has no virtual functions (10.3) and no virtual base classes (10.1),
- has the same access control (Clause 11) for all non-static data members,
- has no non-standard-layout base classes,
- either has no non-static data members in the most derived class and at most one base class with non-static data members, or has no base classes with non-static data members, and
- has no base classes of the same type as the first non-static data member.
在基类子对象内对this指针做放置new操作
这么做是UB的,直接看标准里的代码吧([ISO/IEC 14882:2014 §3.8.5]):
1 |
|
this的生命周期的终结时机为调用析构函数之后,调用析构函数则意味着该类内的所有数据均变成了无意义的存在,对无意义的东西做操作是UB行为。
MinGW-W64编译32位程序
GCC支持-m32参数来将代码编译到32位程序。但是如果你的MinGW是SEH或者DWARF的异常模型,则他们是单一平台的,不支持编译到32位程序。
在stackoverflow上有个回答:How do I compile and link a 32-bit Windows executable using mingw-w64
还有CSDN上的一个问题:MinGW-w64如何编译32位程序
解决办法:可以选择SJLJ的异常模型版本,可以从这里检索下载。也可以使用TDM GCC(目前只更新到了MinGW5.1.0)。
C语言的隐式函数声明
下面的代码:
1 | // hw.c |
使用gcc编译,是会编译成功并且可以执行的(具有警告):
1 | $ gcc hw.c -o hw.exe |
那么问题来了,我在当前的编译单元内并没有包含printf的声明,怎么就可以编译通过呢?
因为C语言的历史上支持过implicit function declaration(C89支持函数的隐式声明):
[ISO/IEC 9899:1990 6.3.2.2] If the expression that precedes the parenthesized argument list in a function call consists solely of an identifier. and if no declaration is visible for this identifier, the identifier is implicitly declared exactly as if. in the innermost block containing the function call. the declaration
1 | extern int idenfifrer () ; |
然而这个特性 C99 就废除掉了:
[ISO/IEC 9899:1999 Foreword] remove implicit function declaration
上面的代码相当于:
- 编译器隐式声明了
printf函数 - 链接器默认链接了
stdlib,所以才不会产生符号未定义的链接错误
在gcc编译器如果不想要默认链接可以使用链接器参数(这里只列出其中的三个):
- -nodefaultlibs: 不使用标准系统库,只有编译参数中指定的库才会传递给链接器
- -nostdlib: Do not use the standard system startup files or libraries when linking.
- -nolibc: Do not use the C library or system libraries tightly coupled with it when linking.
更多的gcc链接参数可以看这里:3.14 Options for Linking
Clang查看对象的内存布局
clang可以在编译时使用-cc1 -fdump-record-layouts参数来查看对象的内存布局。
但是使用上面的命令不会从Path路径查找标准头文件,我们需要先对源文件进行预处理:
1 | $ clang++ gcc -E main.c -o main_pp.cpp |
然后对预处理之后的.cpp文件执行编译时加入-cc1 -fdump-record-layouts参数:
1 | $ clang++ -cc1 -fdump-record-layouts main_pp.cpp |
Example:
1 | // class_layout.cpp |
预处理:
1 | $ clang++ -E class_layout.cpp -o class_layout_pp.cpp |
查看上面三个类的内存布局:
1 | $ clang++ -cc1 -fdump-record-layouts class_layout_pp.cpp |
参考文章:Dumping a C++ object’s memory layout with Clang
虚函数的默认参数根据调用者(指针或引用)的静态类型决定
之前曾经在C/C++标准的一些摘录#override函数不会覆盖其原有默认参数中曾经写道过这点内容,但是不够详细,这里做一个补充。
考虑以下代码:
1 | class A{ |
C++标准中规定了关于虚函数的默认参数使用描述:
[ISO/IEC 14882:2014]A virtual function call (10.3) uses the default arguments in the declaration of the virtual function determined by the static type of the pointer or reference denoting the object.
即,虚函数的默认参数的使用是执行该虚函数调用的指针或引用的静态类型的决定的。
从上面的例子来看:
1 | int main() |
即多态函数的默认参数并不是动态绑定的,并不会在运行时才确定使用继承层次中的哪一个实现的默认参数,而是编译时根据对象的类型就确定了使用哪个默认参数。
可以看一下上面代码的LLVM-IR代码:
1 | define i32 @main() #4 { |
C++ Lambda的捕获
在之前的一篇文章中(lambda在编译器中实现的方式)写道过编辑器中Lambda的结果实际上就是一个重载了()的类。
但是关于捕获的地方有一点需要补充:如何确定捕获的个数?如果使用值捕获[=]或者引用捕获[&]会把之前的所有数据都作为该Lambda的数据成员吗?
带着这个问题,来探究一下。
首先,先说结论:在使用默认捕获[&]/[=]时,并不会把上文中所有的对象都捕获进来,而是在Lambda表达式内部用到了哪几个才会捕获。
看下面的例子:
1 | public: |
先来看一下这个闭包对象的成员(LLVM-IR):
1 | // class A |
因为是值捕获,所以该闭包对象捕获的成员均是一份拷贝。
本来我以为,生成出来的闭包对象应该有一个构造函数,捕获的参数作为构造的参数传进去,不知道是LLVM做了优化还是怎样,没看到有生成出来构造函数,其捕获的初始化部分如下:
1 | define i32 @main() #4 { |
函数类型的typedef不能用在定义
考虑如下情况:
1 | typedef void Func(int); |
[ISO/IEC 14882:2014 §8.3.5.10]A typedef of function type may be used to declare a function but shall not be used to define a function (8.4).
Lambda-Expressions Syntax
首先先来看一下C++标准中对于Lambda-Expressions的Syntax描述(注意也是递归描述的):
下面这个代码表达了什么意思?
1 | int main() |
先看第一行:
1 | [](){}; |
这一行是使用lambda-expression声明了一个Unamed的闭包对象(closure object),不捕获、不传参也不做任何实现。
第二行:
1 | []{}(); |
这个就有点意思了,根据上面的Lambda-Expression Syntax图里标注的那样:${lambda\textrm{-}declarator}_{opt}$是Opt的,表示可以省略。
而${lambda\textrm{-}declarator}$又包括${(parameter\textrm{-}declaration\textrm{-}clause) mutable}_{opt}$等,所以表示lambda表达式在声明时参数列表可以省略。
也就是说:
1 | auto lambdaObj=[](){}; |
这样我们可以理解第二行的前半部分为声明一个闭包对象(closure object),而最后的那个();则是调用该闭包对象。
第三行:
1 | {}[]{}; |
其实这一行也可以这么写:
1 | { |
一个block然后使用lambda-expression创建一个Unamed的闭包对象(closure object)。
C++声明语义的一个坑点
以下代码有什么问题?会输出什么?
1 | class T |
答案是什么都不会输出!
真正执行的语义并不是我们期望的那样:创造一个std::string的临时变量,然后执行临时变量的销毁语义。
因为C++的声明语义规则如下;
注意上面图里是递归描述的。
1 | std::string(hw); |
所以在print函数里,是创造了一个std::string的局部变量(local-scope)hw,把类范围(class-scope)的hw给隐藏了。
解决办法:使用{}代替(),上面的例子里使用initializer-list会调用copy-constructor,然后立刻销毁该临时对象。
在当前的这个例子里,还没什么危害,如果在多线程编程里对锁进行这样的操作那就十分令人窒息了。
VC越界输出烫烫烫的原因
在当年用VC学习C语言时,在遇到内存访问越界的时候会看到输出烫烫烫等”类似乱码”的东西。
例如下面的代码(使用vs2017-debug-x86编译):
1 | int main() |
x32dbg调试: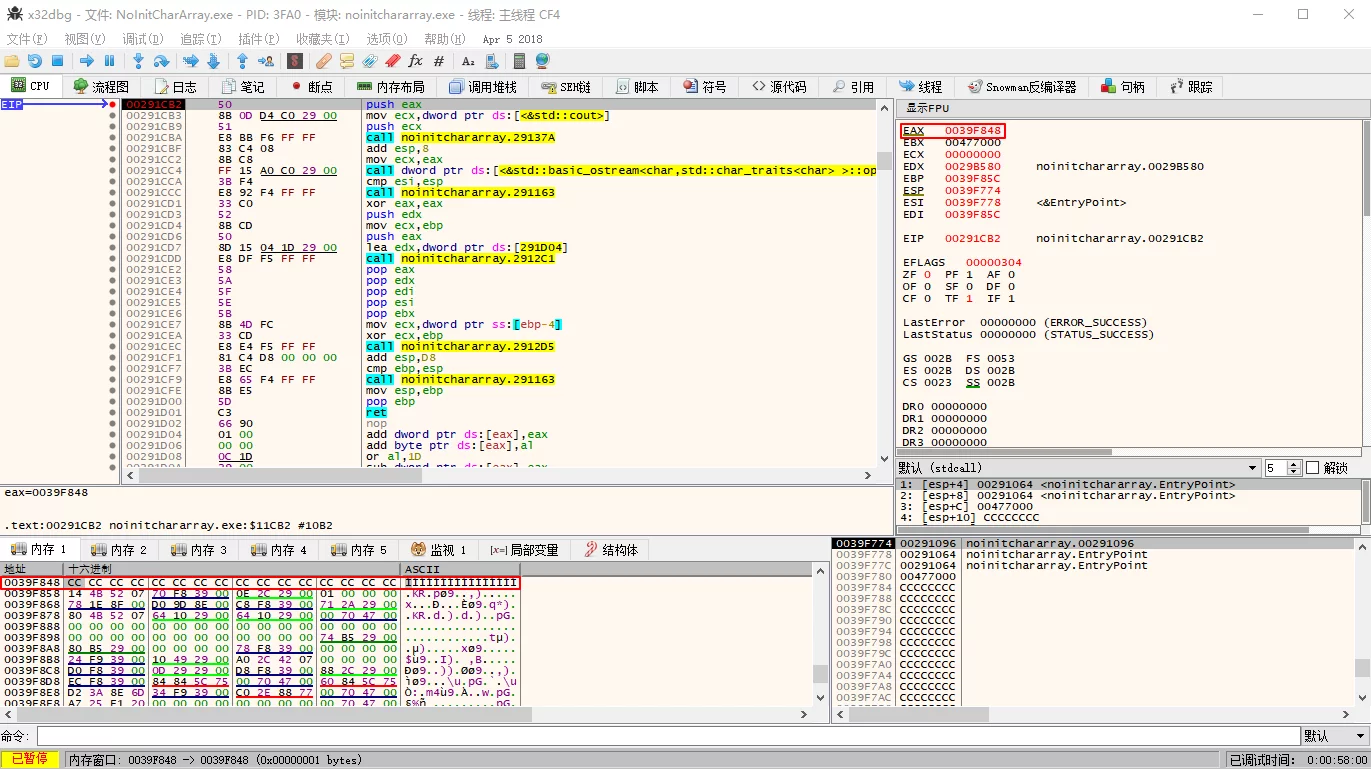
通过IDA调试: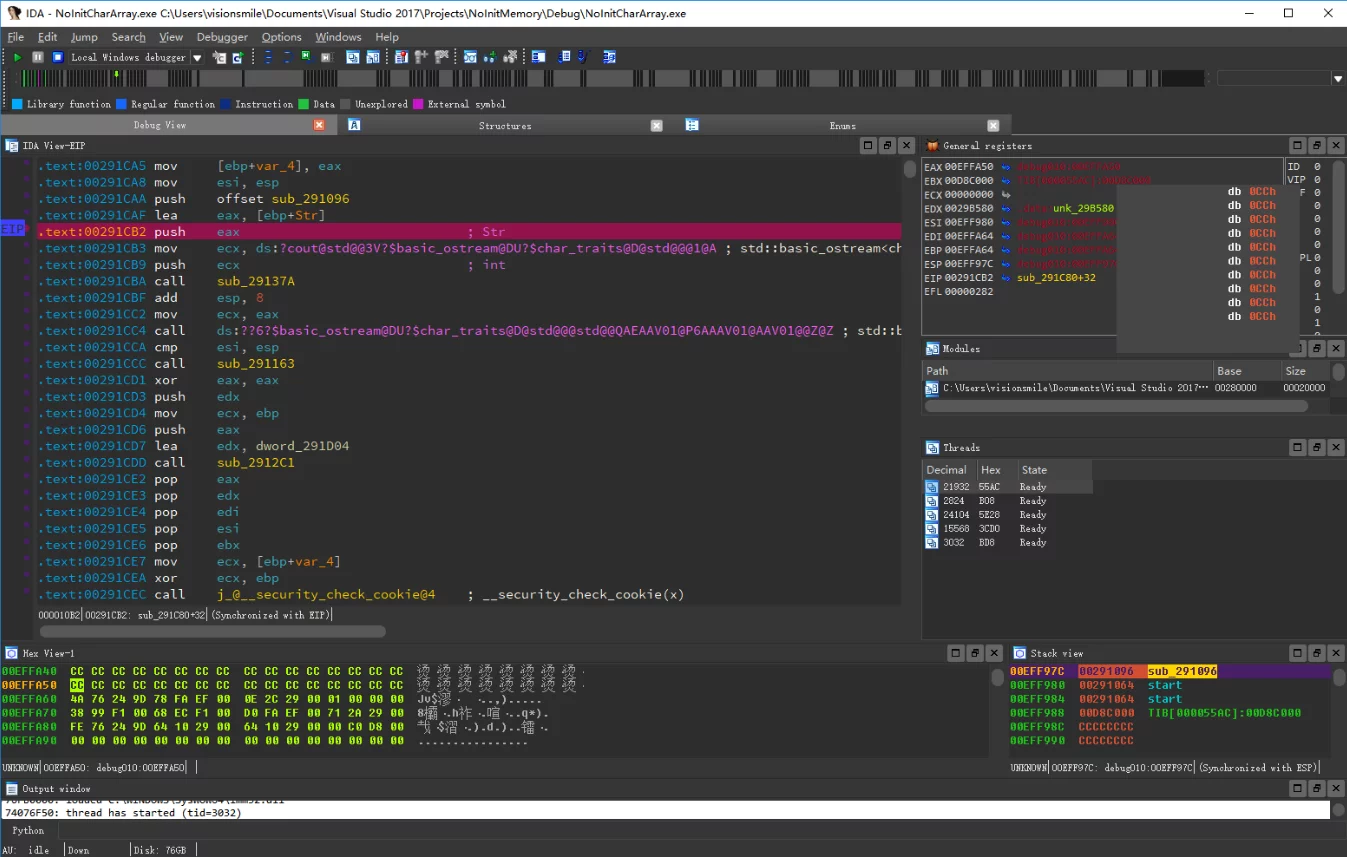
运行结果: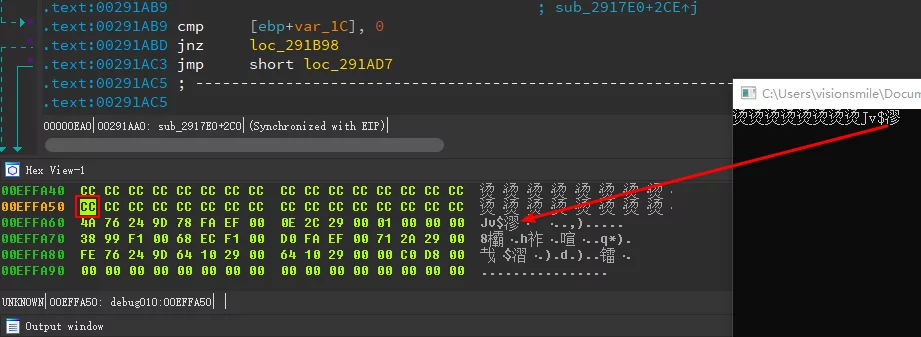
其实时因为,VC在debug模式下,会将未初始化的内存设置为0xCC,而中文的GBK编码下0xCC恰好就是烫。
Clang的一个Bug
1 | class A{ |
上面的代码通过Clang编译运行会输出bbb(使用最新的Clang5.0也是如此),而GCC则产生一个重定义错误。
先挖坑了,有时间再分析一下这个问题。
ISO C与POSIX对Byte定义的区别
ISO C
byte
addressable unit of data storage large enough to hold any member of the basic character set of the execution environment
NOTE 1 It is possible to express the address of each individual byte of an object uniquely.
NOTE 2 A byte is composed of a contiguous sequence of bits, the number of which is implementation-defined. The least significant bit is called the low-order bit; the most significant bit is called the high-order bit.
POSIX
Byte
An individually addressable unit of data storage that is exactly an octet, used to store a character or a portion of a character; see also Section 3.87 (on page 47). A byte is composed of a contiguous sequence of 8 bits. The least significant bit is called the ‘‘low-order’’ bit; the most significant is called the ‘‘high-order’’ bit.
Note: The definition of byte from the ISO C standard is broader than the above and might accommodate hardware architectures with different sized addressable units than octets.
sizeof size of reference member of class
1 | struct ATest{ |
上面类ATest在LLVM/Clang下编译的内存布局为:
1 | %struct.ATest = type { i32* } |
至于引用为什么是指针,具体请看引用的实现。
所以sizeof(ATest)在这个实现下的结果是8。
What is Translation Unit in C/C++?
[ISO/IEC 14882:2014]A source file together with all the headers (17.6.1.2) and source files included (16.2) via the preprocessing directive
#include, less any source lines skipped by any of the conditional inclusion (16.1) preprocessing directives, is called a translation unit. [ Note: A C ++ program need not all be translated at the same time. — end note ]
[ISO/IEC 9899:1999]
A source file together with all the headers and source files included via the preprocessing directive#includeis known as a preprocessing translation unit. After preprocessing, a preprocessing translation unit is called a translation unit.
C语言跨scope的变量访问
如果具有下面的C语言代码,并且使用C编译器编译。
1 | int i=123; |
因为在C语言中因为没有namespace的概念,所以不能用C++中的::来限定操作。
但是可以使用下面的骚操作来实现:
1 | int i=123; |
Google C++ Style Guile
简易图片版: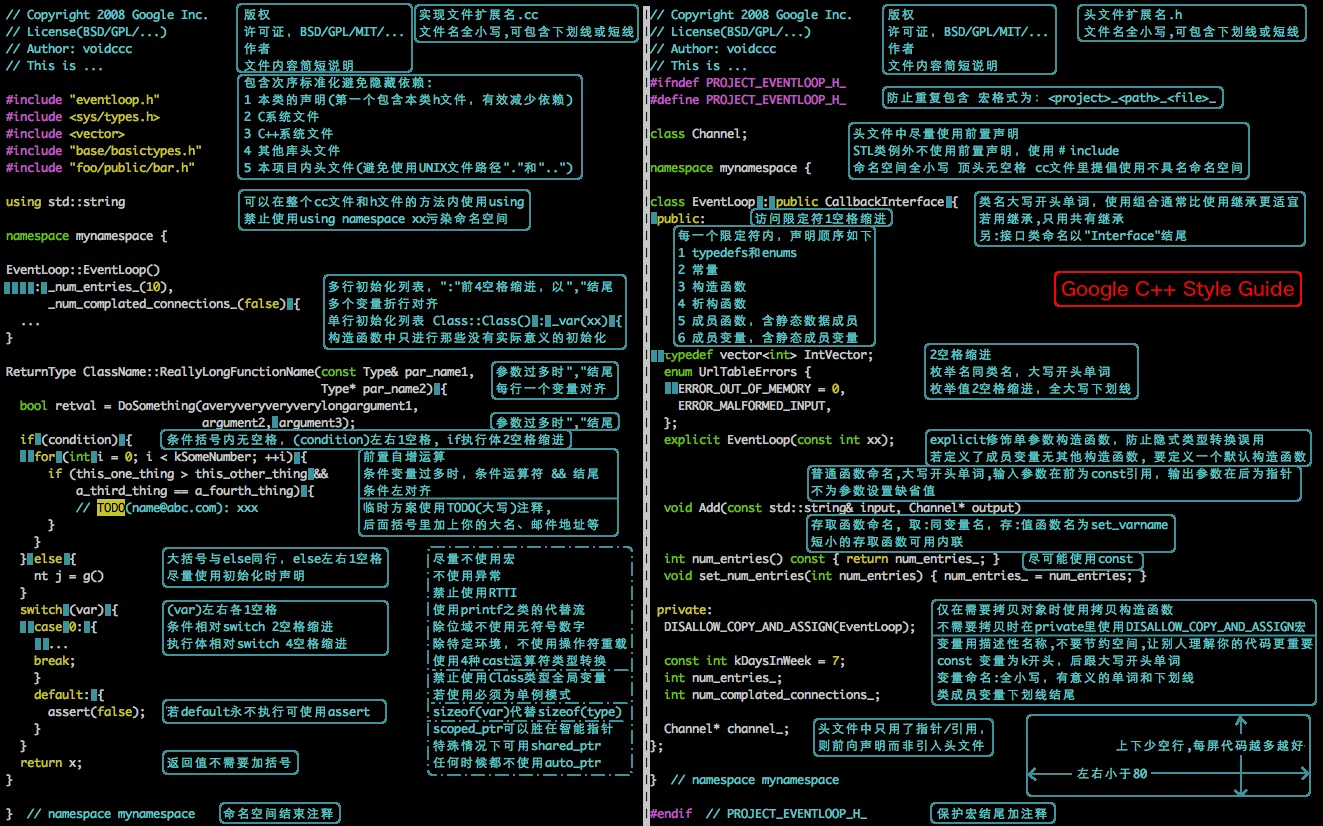
中文PDF版:
C++17特性速查表
值类别速查表
C++11的新特性与兼容性
new、构造函数和异常
new操作实际上是由两个部分组成的:
- 首先调用operator new分配内存
- 调用对象的构造函数
Evaluation of a new expression invokes one or more allocation and constructor functions; see 5.3.4
这很重要,虽然一般情况下没有什么问题,但是考虑到异常安全这就是很重要的:如果new一个对象时抛出异常如何判断是operator new抛出了异常还是类的构造函数抛出了异常?
如果operator new抛出了异常,则没有任何内存被分配(抛出std:;bad_alloc),也就不应该调用operator delete,但是如果是类的构造函数中抛出异常,说明内存已经分配完毕,则我们就需要调用operator delete来执行清理操作。
指针比较的含义
在C++中,一个对象可以具有多个有效的地址,因此,指针比较不是地址的问题,而是对象同一性的问题。
C++中常见术语错误
一个比较常见的问题是,不同语言间对于实现相同行为的描述术语也都不相同。比如Java或者其他语言用方法(method)来描述类内的函数,而C++里是没有方法(method)这个概念的,应该称为成员函数(member function)。
在C++中比较常出错的有以下几种术语:
| Wrong | Right |
|---|---|
| Pure virtual base class | Abstract class |
| Method | Member function |
| Virtual method | ??? |
| Destructed | Destroyed |
| Cast operator | Conversion operator |
为什么要有引用?
我觉得C++具有引用的有两个基本原因:
- 防止对象拷贝带来的开销(比指针的间接访问要更简洁)
- 对于IO流的使用(比如cout<<x<<y返回流的引用等价于使用cout<<x,cout<<y)
C++一些语言特性被设计的原因
- 名字空间就是针对不同库里使用相同的名字而提供的机制
- 异常处理是为建立一种处理错误的公共模型提供了基础
- 模板是为定义独立于具体类型的容器类和算法而提供的一种机制,其中的具体类型可以由用户或者其他的库提供
- 构造函数和析构函数为对象的初始化和最后清理提供了一种公共模型
- 抽象类提供了一种机制,借助于它可以独立地定义接口,与实际被接口的类无关
- 运行时类型信息是为了寻回类型信息而提供的一种机制,因为当对象被传递给一个库再传递回来的时候,可能只携带着不够特殊(基类的)类型信息。