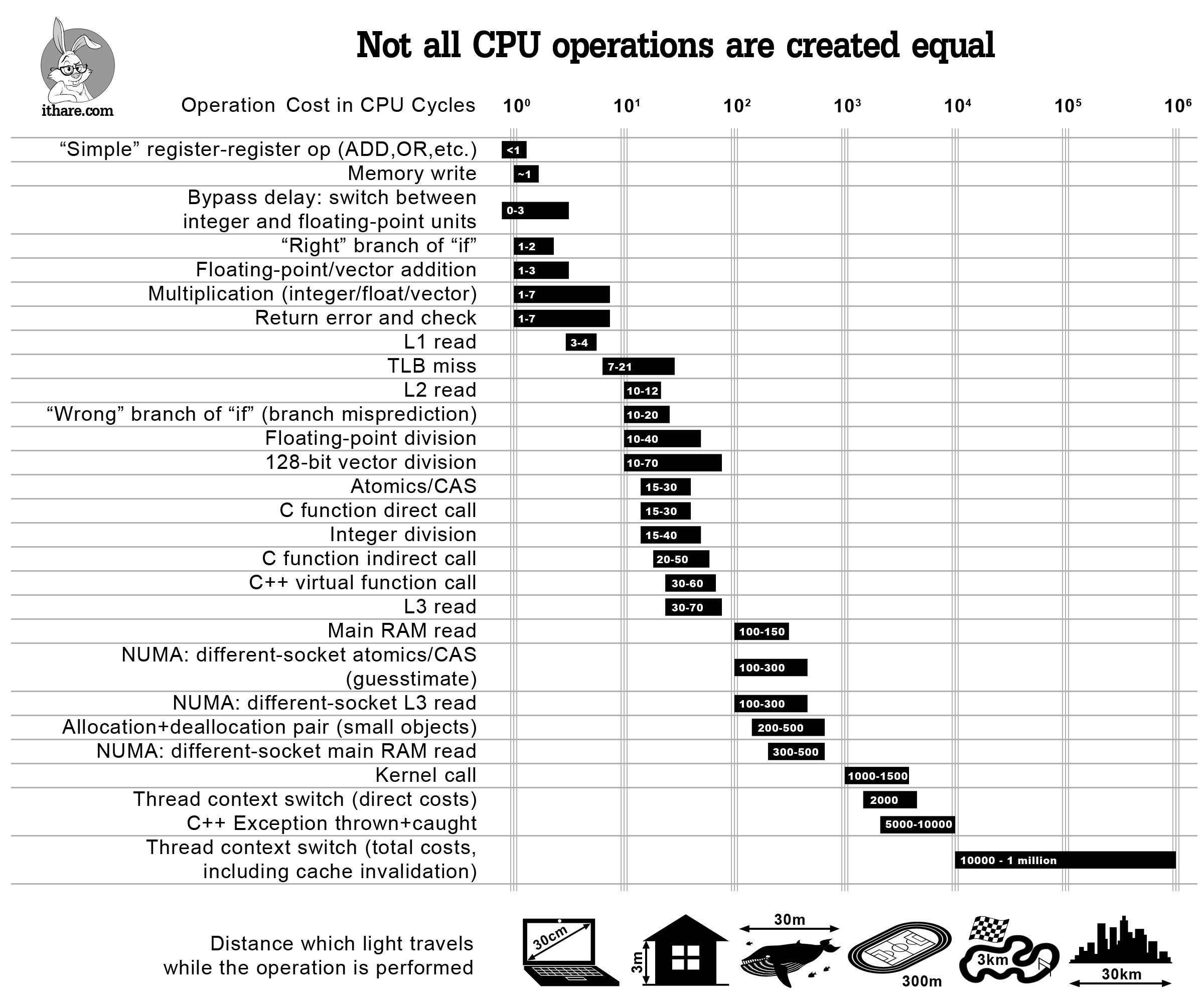
CPU时钟周期的运行成本
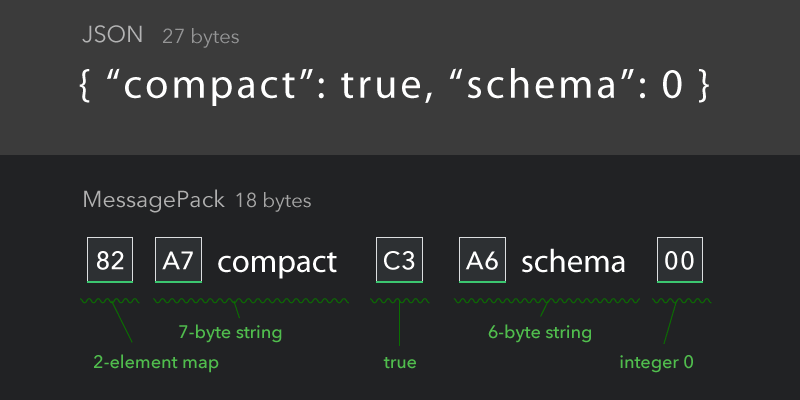
messsagepack
msgpack是一种二进制的json方案:
Bitcon论文
中本聪的去中心化货币论文:
英文原版下载:Bitcoin:A Peer-to-Peer Electronic Cash System
mov是图灵完备的论文
汇编语言里的mov就是图灵完备的:
a/lib格式
.a和.lib是静态链接库格式,它们是ar压缩的.o和.obj文件,并且内部有txt文件来记录每个目标文件中的符号信息。
在IOS和MacOS上的txt中的符号名都以_开头。
JNI调用签名对照表
Java中的基础类型和签名对照:
| Java | Native | Signature |
|---|---|---|
| byte | jbyte | B |
| char | jchar | C |
| double | jdouble | D |
| float | jfloat | F |
| int | jint | I |
| short | jshort | S |
| long | jlong | J |
| boolean | jboolean | Z |
| void | void | V |
如下列函数的签名为()V:
1 | public void AndroidThunkJava_SetFullScreenDisplayForP(); |
非内置类型的签名规则为:
- 以
L开头 - 以
;结尾 - 中间用
/隔开包和类名
如Java中的String:
1 | // ()Ljava/lang/String; |
注:括号内是参数的签名,括号右侧是返回值类型的签名。
如:
1 | // (Ljava/lang/String;Ljava/lang/String;)I |
信号量的竞态条件
[CSAPP,2E,12.5.2]当有多个线程在等待同一个信号量的时候,不能够预测V操作要重启哪个线程。
内存对齐的作用
之前写过一篇文章来介绍C++里内存对齐的规则:结构体成员内存对齐问题
但是,为什么呢?
首先,内存中数据的排列方式被称为内存布局。结构中不同的排列方式,占用的内存不同,也会简介影响CP访问内存的效率(无论是否对齐,CPU都可以正常处理,但又效率问题)。为了权衡空间占用情况和访问效率,引入了内存对齐规则。
CPU在单位时间内能处理的一组二进制数称为字,这组二进制数的位数称为字长。如果是32位CPU,其字长位32位也就是4字节。一般来说,字长越大,计算机处理信息的速度就越快。
以32位CPU为例,CPU每次只能从内存中读取4个字节的数据,所以每次只能对4的倍数的地址进行读取。
假设现在有一个4字节整数类型数据,首地址并不是4的倍数,假定位0x3,则该类型存储在地址为0x3~0x7的内存空间中。因此CPU如果像读取该数据,则需要分别在0x1和0x5处进行两次读取,而且还需要对读取到的数据进行处理才能得到该整数,如图:
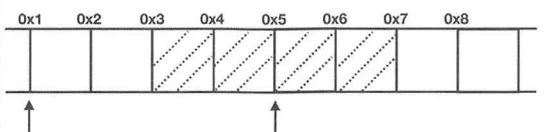
CPU的处理速度比从内存中读取数据的速度快很多,所以减少CPU对内存空间的访问是提供程序性能的关键。因此采取内存对齐策略是提高程序性能的关键,因为是32为CPU,所以只需要按4字节对齐,上面的例子可以变为CPU只需要读取一次:
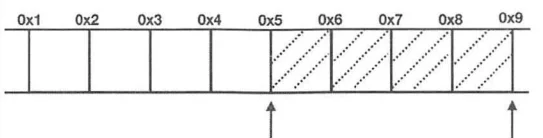
因为对齐的是字节,所以内存对齐也叫字节对齐。内存对齐在C++中是编译器处理的,一般不用人为指定,但是需要了解内存对齐的规则,这样有助于写出既节省内存又性能最佳的程序。
参考资料:
- 《Rust编程之道》4.1.3 P101.
- 《深入理解计算机系统第三版》3.9.3 P189
检查二进制文件的Runtime Library类型
在之前的笔记中写到过,在VS中编译C++项目时,可以指定生成目标的Runtime Library类型:MT与MD。
之前的笔记中也写到了使用dumpbin.exe来判断一个二进制文件的平台信息(x86/x64),现在有了一个类似的问题,怎么判断一个二进制文件的Runtime Library是MT还是MD呢?
回答这个问题,依然要用dumpbin.exe这个工具,通过查看二进制文件依赖的DLL信息来判断它的Runtime Library类型,但是这个方法的缺点是没办法判断是Debug还是Release的,一般混用debug/release的链接库会连接错误。
使用下列命令:
1 | dumpbin.exe BINARY_FILE /dependents | findstr dll |
如果具有以下输出,则是MD的:
1 | MSVCP140.dll |
之所以可以断定他是MD的,是因为这个二进制文件中依赖了CRT DLL.
修改Runtime library的类型为MT之后,再次测试:
1 | KERNEL32.dll |
只有一个KERNEL32.dll,不依赖任何其他的CRT DLL,所以他是MT的。
查看二进制文件是x64还是x86版本
给一个dll或者lib,怎么判断它是64位还是32位的呢?
可以使用VS工具链中的dumpbin查看可执行文件中的各个段,文件头中有machine的信息,如果没有装VS,可以在这里下载,Github上有人开发了一个GUI版本(DumpbinGUI),但是Release中没有提供二进制下载,我编译了一下可以在这里下载。
然后使用命令:
1 | $ dumpbin.exe /headers EXECUTABLE_FILE |
后面的一堆可以不看,需要关注的重点就是machine这一项,对于64位的文件这里是x64,32位的就是x86。
Guide to x86-64
浮点的零值
浮点的零值应该用0.0f,因为浮点值并不是精确存储的,有浮点舍入,所以不能用位全为0的0.0比较。
sendfile的优势
通常,我们从一个文件描述符fd中读取数据,然后再写入另一个fd:
1 | while ((n = read(diskfilefd, buf, BUZ_SIZE)) > 0) |
但是频繁传输使用这样的方式很不高效,为了传输文件必须使用两个系统调用:一个用来将文件内容从内核缓冲区cache拷贝到用户空间,另一个来将用户空间缓冲区拷贝至内核空间,以此进行传输。
但是如果我们只是传输而不对传输的数据进行任何处理这种两步式的操作就是一种浪费。
系统调用sendfile就是被设计为来抵消这种低效性。
Unix system call interface:sendfile
1 |
|
其作用为:
transfer data between file descriptors
比如,当我们通过socket描述符来传输数据时,通过sendfile会直接将数据传送到套接字上,而不会经过用户空间,这种技术叫做**零拷贝传输(zero-copy transfer)**。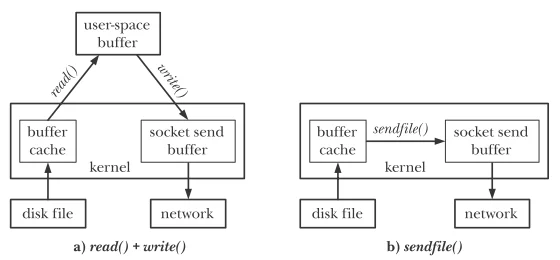
系统调用sendfile在代表输入文件的描述符in_fd和代表输出的描述符out_fd之间传送文件内容(字节)。描述符out_fd必须指向一个套接字。参数in_fd指向的文件必须是可以进行mmap()操作的。在实践中,这通常表示一个普通文件,这些局限多少限制了sendfile的使用。我们可以使用sendfile将数据从文件传递到套接字上,但反过来就不行。另外,我们也不能通过sendfile在两个套接字之间直接传送数据。
在Linux2.4以及早期版本中,out_fd是可以指向一个普通文件的。
并发和并行(concurrency and parallel)
以下内容摘自CASPP,2e(其实用流描述并行和并发是依赖于操作系统实现的)
A logical flow whose execution overlaps in time with another flow is called a concurrent flow, and the two flows are said to run concurrently. More precisely, flows X and Y are concurrent with respect to each other if and only if X begins after Y begins and before Y finishes, or Y begins after X begins and before X finishes. For example, in Figure 8.12, processes A and B run concurrently, as do A and C. On the other hand, B and C do not run concurrently, because the last instruction of B executes before the first instruction of C.
The general phenomenon of multiple flows executing concurrently is known as concurrency. The notion of a process taking turns with other processes is also known as multitasking. Each time period that a process executes a portion of its flow is called a time slice. Thus, multitasking is also referred to as time slicing. For example, in Figure 8.12, the flow for Process A consists of two time slices.
Notice that the idea of concurrent flows is independent of the number of processor cores or computers that the flows are running on. If two flows overlap in time, then they are concurrent, even if they are running on the same processor. However, we will sometimes find it useful to identify a proper subset of concurrent flows known as parallel flows. If two flows are running concurrently on different processor cores or computers, then we say that they are parallel flows, that they are running in parallel, and have parallel execution.
为什么socket的IP地址是一个结构?
一个IPv4的地址就是一个32位的无符号整数。但是经常通过一个in_addr这个结构来存储。
该结构定义在<netinet/in.h>头文件中:
The <netinet/in.h> header shall define the in_addr structure, which shall include at least the following member:
1 | struct in_addr{ |
in_addr_t Equivalent to the type
uint32_tas described in<inttypes.h>.
但是为什么要用一个结构来存放IP地址呢?
[CSAPP,2e]把一个标量地址存放在结构中,是socket接口早期实现的不幸产物。为IP地址定义一个标量类型应该更有意义,但是现在更改已经太迟了,因为已经有大量应用基于此了。
TCP/IP协议族
TCP/IP的协议族是一组不同的协议组合在一起构成的协议族(应用层协议(FTP/Telnet等)、运输层(TCP/UDP)、网络层(IP/ICMP/IGMP)、链路层(设备驱动程序及网络接口设备))。尽管通常称该协议族为TCP/IP,但TCP和IP只是其中的两种协议而已。
POSIX data types
[IEEE Std 1003.1™ 2008]The implementation shall support one or more programming environments in which the widths of
blksize_t,pid_t,size_t,ssize_t, andsuseconds_tare no greater than the width of typelong.
MMU和COW
来看一下COW的一个实例:在child process中修改从parent process中获取到的变量触发COW然后对child process和parent process中的分别取地址,可能会获取到相同的结果,但是他们并不在位于一个物理地址。
1 |
|

看上面的运行结果图,在运行时可以看到在子进程中对x取地址和父进程中对x取地址得到的结果相同,简单直觉上这不符号COW的规则,子进程中在对x写入操作时应该与原来父进程的地址是不一样的。
原因就是&取得的是虚拟地址,不同进程的同一个虚拟地址被MMU映射到不同的物理地址。所以他们的虚拟地址虽然相同,但是他们实际上还是指向不同的物理地址的。