C和C++均使用分离编译来支持多源文件模块化机制,但是为什么这么做以及如何做是个值得探讨的问题。本篇文章并非是讲述C和C++中如何才能产生不同链接的语法规则,而是分析下C/C++编译器是如何实现编译和链接模型的。
在介绍下面的内容之前先来了解一下Translation environment的概念:
[ISO/IEC 9899:1999]**A C program need not all be translated at the same time.The text of the program is kept in units called **source files, (or preprocessing files) in this International Standard.A source file together with all the headers and source files included via the preprocessing directive
#includeis known as a preprocessing translation unit. After preprocessing, a preprocessing translation unit is called a translation unit.
Previously translated translation units may be preserved individually or in libraries. The separate translation units of a program communicate by (for example) calls to functions whose identifiers have external linkage, manipulation of objects whose identifiers have external linkage, or manipulation of data files. Translation units may be separately translated and then later linked to produce an executable program.
主要要明白翻译单元(translation unit)的概念,既是源文件通过预处理器之后产生的代码(所有的#define宏被替换,条件编译#ifndef/#endif以及#include的文件被包含进来)。
如:
1 | // main.c |
通过预处理器之后:
1 | # 文章后面会讲到gcc的这些参数的含义 |
输出的文件main.i即是main.c通过预处理器之后的翻译单元,它包含头文件stdio.h中的所有文本以及main.c中的所有文本。
碍于篇幅,不在本篇文章中贴出main.i的信息,我将其放在的Gist上:hxhb/main.i,可以在里面看到main.c经过预处理器之后的状态。
本文主要讨论的内容也即是在不同的翻译单元里如何引用相同符号(链接模型)。
分离编译
C和C++中源代码不是直接一步被编译为操作系统可执行的可执行目标文件(executable object file)**的,而是通过几个步骤来实现的分离编译——多个源文件被分别编译成几个单独的模块(一个程序具有多个翻译单元),最后在统一把这几个模块拼接(**链接linkage)起来,才组成了可执行的二进制。(后面会提到声明与定义分离的原因)
C++中也使用了相同的编译模型,是从C中继承来的,原因在于C++要设计之初的目的之一就是与C兼容(还有零开销(如果不使用语言的某一部分特性不应该被带来额外的开销)以及值语义(对象拷贝之后就与源对象无关)),详情可看C++之父Bjarne的著作《The Design and Evolution of C++》。
“与C兼容”这个含义很丰富,不仅仅是兼容C的语法,更重要的是兼容C语言的编译模型与运行模型,也就是说能直接使用C语言的文件和库。——陈硕《Linux多线程服务端编程:使用muduo C++网络库》
实际上C++的编译模型要比C的复杂得多,本文旨在提供一种分离编译的概念及实现方式,更具体地内容我会写在后续的文章中。
早期的C语言编译器并不是一个单独的程序(现在的编译器也很多是由单独功能的程序模块组成的编译工具链),Dennis Ritchie为PDP-11编写的C语言编译器是七个可执行文件组成的:cc/cpp/as/ld/c0/c1/c2。
为什么要这么做?
其实主要原因是早期的计算机性能十分有限,而上面所提到的Dennis Ritchie最初所使用的PDP-11只有24KB内存,其中16KB运行操作系统,8KB运行用户代码,所以碍于性能限制编译器没办法在内存里完整地表示单个源文件的抽象语法树,更不可能把整个编译器运行在内存里。所以,由于内存限制,C语言使用分离式编译,可以分别地编译多个源文件,生成多个目标文件,然后再想办法将他们组合到一起(链接),使之可以在有限地内存中完整编译出一个可执行文件。
GCC编译器
现代编译器(GCC/Clang)则也通常由预处理器、编译器、汇编器、链接器四部分组成。
可以在GCC的gcc --help中看到相关编译参数及其含义:
| 参数 | 含义 |
|---|---|
| -E | Preprocess only; do not compile, assemble or link. |
| -S | Compile only; do not assemble or link. |
| -c | Compile and assemble, but do not link. |
| -o <file> | Place the output into <file>. |
| -pie | Create a position independent executable. |
| -shared | Create a shared library. |
| -x <language> | Specify the language of the following input files. Permissible languages include: c c++ assembler none’none’ means revert to the default behavior ofguessing the language based on the file’s extension. |
| -Wl,<options> | Pass comma-separated <options> on to the linker. 在生成动态链接库的时候可以传递给链接器参数生成导入库 |
ld(linker)的参数(ld --help):
| 参数 | 含义 |
|---|---|
| –out-implib <file> | Generate import library 生成共享库的导入库 |
注:动态链接库一般需要生成一个导入库,方便静态程序编译时来载入动态链接库,否则就需要自己LoadLibrary来载入DLL文件,并使用GetProcAddress来获取对应的函数指针(DLL)。
有了导入库,只需要在编译代码时链接进来导入库,就在包含动态链接库的头文件后直接在代码中使用动态链接库的函数了。
ldd:输出程序依赖的共享库,用法:
1 | $ ldd main.exe |
简单地说,gcc中编译一个源文件需要四步:
- 预处理(-E)
- 编译器(-S)
- 目标文件(-c),
- 链接(无参)
看到上面的东西可能会有点绕,但是简单来说,允许分离编译的含义在于:多源文件模块化机制。即我可以在我当前的模块源文件中使用其他源文件中的代码,而不用把所有的代码都放到单一的源文件中。
就像书籍中的交叉引用一样,我告诉你另一本书的第几章第几小节讲述了一个什么东西,我在当前的文章中引用到了它所定义的概念,其相关的含义你需要去翻我所指定的那本书才能知道它所代表的是什么。
TCPL中关于链接中内部链接和外部链接的介绍:
Within a translation unit, all declarations of the same object or function identifier with internal linkage refer to the same thing, and the object or function is unique to that translation unit. All declarations for the same object or function identifier with external linkage refer to the same thing, and the object or function is shared by the entire program.
注意:C语言中函数声明(没有指定链接)具有隐式的外部链接。
**[ISO/IEC 9899:1999]**If no prior declaration is visible, or if the prior declaration specifies no linkage, then the identifier has external linkage.
这意味着:
1 | extern int max(int,int); |
两者之间具有相同的含义。
如果想要显式指定一个标识符为内部链接(internal linkage),可以将其声明为
static.
**[ISO/IEC 9899:1999]**A function declaration can contain the storage-class specifier static only if it is at file scope;
编译链接实例
在C语言中使用extern关键字来指定一个名字具有外部链接:
1 | // main.c |
而函数int max(int,int)的实现(define)是在另一个文件中:
1 | // maxDefine.c |
利用上文中写到的编译四步,我们来尝试一下使用分离编译来手动编译和链接这两个源文件。
首先,先对其中的一个源文件执行预处理(#include/条件编译/宏展开)
1 | # 将预处理之后的文件放至main.i |
然后对预处理后的文件执行编译(从预处理文件生成汇编代码):
1 | # 将编译后的结果放至main.s |
由上一步得到的汇编代码main.s使用-c来生成目标文件(从汇编代码生成目标文件):
1 | # 将目标文件存储为main.o |
可以看到分别生成了main.i/main.s/main.o三个文件: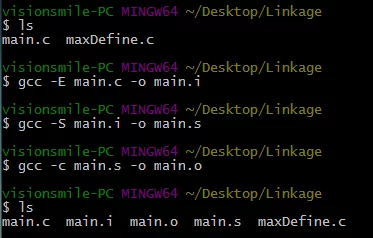
然后对maxDefine.c也执行同样的操作,同样也会生成maxDefine.o,接下来我们来尝试链接:
1 | # 无参gcc/g++为链接目标文件 |
不出意外,会在当前目录下生成一个a.exe,这就是我们需要的可执行程序。
链接是什么行为?
但是,中间发生了什么?为什么在main.c中没有定义max它就正确找到在maxDefine.c中找到max的定义呢?
我画了一个简单的示意图: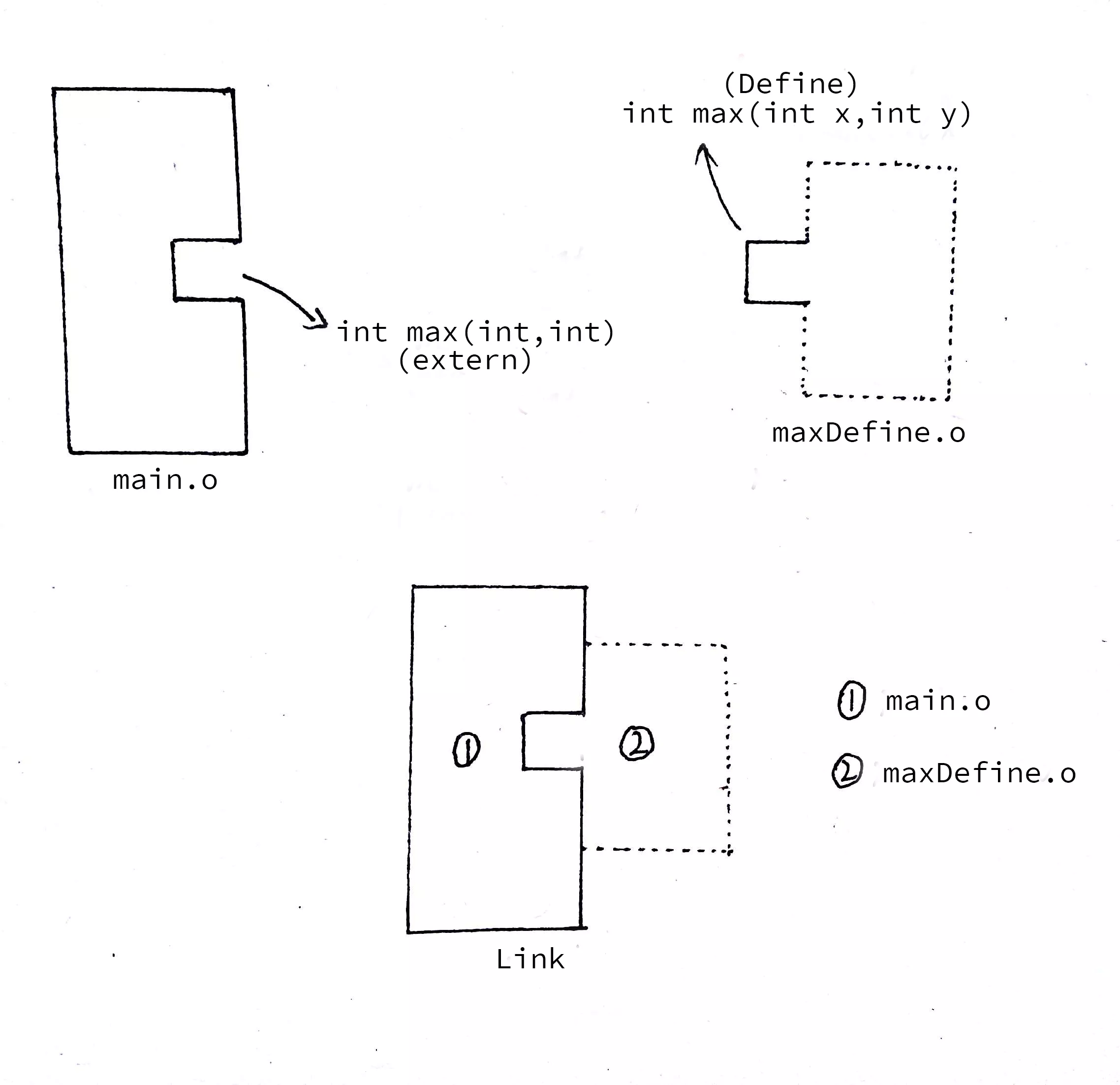
在main.c中使用extern int max(int,int)相当于在其的目标文件上挖了一个叫做max插槽,而maxDefine.c里对max的定义相当于创造了一个对应max槽的钥匙。
当我们只使用main.o进行链接时,会产生undefine reference错误(其实很多C/C++编程中的错误都不是编译错误,而是链接错误)。
即如果我们链接main.o时不指定maxDefine.o,则会产生一个链接错误:
1 | $ gcc main.o |

这就相当于想要打开门却没有钥匙,当然会报错了。
注意:函数原型和定义在不同的翻译单元不完全符合在C语言中也并不是一个错误。比如,我将maxDefine.c中的max定义改为int max(int x,double y)依然可以链接并执行成功(C语言具有整型提升和隐式转换,在main函数中对max的调用,第二个参数被隐式转换为double,返回类型规则相同)。因为C语言的函数符号在目标文件中不依赖任何参数类型,仅仅依赖于函数的标识符名称(函数max虽然在main.c和maxDefine.c源文件中的类型不同,但是在他们的目标文件中,函数max的符号信息均为max,所以符号匹配会成功),C语言就是这么相信程序员,这也是通常所说的C语言比C++更自由更不安全的体现之一。
而上面的问题在C++中则是一个错误,因为在main.c中声明的max为int max(int,int),因为上文已经提到的C++的目标文件中的符号信息依赖于函数名和依赖参数类型进行名称改编,所以int max(int,int)与int max(int,double)在目标文件中是两个不同的符号,所以会造成未定义符号错误。
GCC工具链编译和链接参数
1 | # 预处理:#include和宏定义以及条件编译 |
目标文件中常见的符号类型:
- A 该符号的值在今后的链接中将不再改变;
- B 该符号放在BSS段中,通常是那些未初始化的全局变量;
- D 该符号放在普通的数据段中,通常是那些已经初始化的全局变量;
- T 该符号放在代码段中,通常是那些全局非静态函数;
- U 该符号未定义过,需要自其他对象文件中链接进来;
- W 未明确指定的弱链接符号;同链接的其他对象文件中有它的定义就用上,否则就用一个系统特别指定的默认值。
- R符号位于只读数据区。比如C语言中的
file scope的const int(C语言和C++不同)。
更多的关于目标文件的符号解释可以看这篇文章:nm目标文件格式分析。
为什么声明和定义要分离?
前面已经提到过了“分离编译”的作用及实现,但是对于C/C++中经常用到的“定义与实现分离”的含义又是什么呢?
其实主要是为了防止多个源文件同时包含同一个源文件时的造成的多重定义(multiple define):
假如现在有三个源文件customMax.cpp/libMin.cpp/main.cpp:
1 | // customMax.cpp |
而在另一个源文件libMin.cpp中#include了customMax.cpp这个源文件:
1 | // libMin.cpp |
而在第三个源文件main.cpp中引入customMax.cpp,但是通过外部链接extern来指定libMin.cpp中的符号libMin:
1 | // main.cpp |
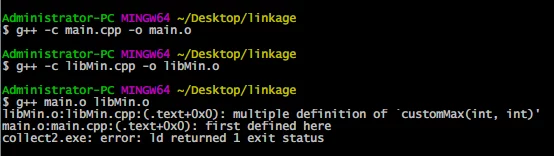
对上面的main.cpp代码与libMin.cpp执行链接时会出现**多重定义(mulit define)**错误:
1 | $ g++ -o main main.cc libMin.cpp |

这是由于int customMax(int,int)的定义和实现是放在一起的,但是在libMin.cpp中和main.cpp中都包含了customMax.cpp源文件,这里main.cpp和libMin.cpp是两个翻译单元。
其相当于:
1 | $ g++ -c main.cpp -o main.o |
来查看一下两个目标文件main.o和libMin.o中的符号信息: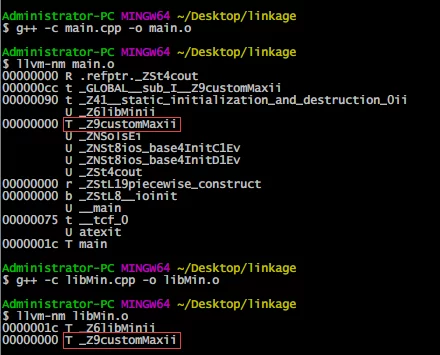
可以看到画红框的部分,回想一下上部分目标文件中常见的符号类型中T代表着什么,这意味着customMax的符号在两个目标文件中均有定义,所以链接时会出现重定义错误。
解决这样问题的办法就是:保持只包含一次实现,在使用时仅包含声明。所以采用声明与实现分离机制。
1 | // customMax.h |
将其定义在别处:
1 | // customMax.cpp |
然后在别的源文件中只包含customMax.h:
1 | // main.cpp |
以及在libMin.cpp中也只是包含customMax.h:
1 |
|
对其两个编译单元分别生成中间文件并查看其符号:
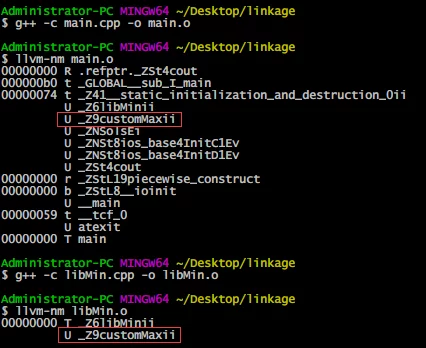
可以看到,此时两个目标文件中均是未定义customMax的符号了。
这样我们就可以在编译时指定customMax的符号来供两个翻译单元使用:
1 | # 生成customMax的目标文件 |
然后,将main.o与libMin.o还有customMax.o链接在一起:
1 | $ g++ main.o libMax.o customMin.o -o main.exe |
当然上面分开操作十分繁琐(只是为了演示),我们也可以一行把上面的操作执行完毕:
1 | # 在多个翻译单元只包含声明,此时就不会提示链接错误了 |
小结:实现和定义分离是为了使多个翻译单元使用相同的符号信息而不会产生多重定义错误而引入的。
注意:C++中模板的声明和定义必须放在一起,这是另一个坑,暂时先按下不表。
C++模板的链接
因为C++模板需要通过在编译时实例化出相应的对象,所以C++中模板的代码必须要是以源码的方式分发,即共享实现必须要把这部分代码公布。
从源代码角度来看,模板代码和内联代码没什么区别(尽管模板并不一定要声明为内联的):模板的全部代码对于使用它的客户代码来说必须是完全可见的。这被称为包含模式,因为基本上我们必须在模板头文件中包含所有的模板定义代码。
来看一个多个翻译单元包含同一个(符号)实现例子:
1 | // max.cpp |
1 | // main.cpp |
1 | // delegateMax.cpp |
主要的问题是main.cpp与delegateMax.hpp这两个翻译单元。
我们来编译和链接一下:
1 | $ clang++ -c main.cpp -o main.o |
会产生符号max(const int&,const int&)的重定义错误。
但是如果把max(const int&,const int&)的实现修改为模板或者inline实现:
1 |
|
再次编译且链接:
1 | $ clang++ -c main.cpp -o main.o |
这次可以链接通过,并没有链接时的重定义错误。
但是对比前后两次main.o与delegeteMax.o中的符号信息没有差别,为什么会造成两次链接的结果不同呢?
这是因为C++中non-member function template模板的代码是具有不同于普通的函数定义的:
C++标准里对于在global scope声明对象的链接描述:
**[ISO/IEE 14882:2011]**A name declared in a namespace scope without a storage-class-specifier has external linkage unless it has internal linkage because of a previous declaration and provided it is not declared const. Objects declared const and not explicitly declared extern have internal linkage.
所以第一次我们声明的max(const int&,const int&)是具有外部链接的符号,而main.o与delegateMax.o中引入了它的实现,所以也分别包含了max(const int&,const int&)具有外部链接的符号,故而才会在链接main.o与delegateMax.o时产生重定义错误。
但是C++中非成员函数模板(non-member function template)的链接却不同于普通的函数:
**[ISO/IEE 14882:2014]**A template name has linkage (3.5). A non-member function template can have internal linkage; any other template name shall have external linkage. Specializations (explicit or implicit) of a template that has internal linkage are distinct from all specializations in other translation units.
即通过模板实现的max(const T&,const T&)是具有内部链接internal linkage的符号,所以在链接时main.o与delegateMax.o中对于max的调用查找只能够找到自己目标文件中的符号名(内部链接外部不可见),所以就会链接成功。
而也正是如此,才能够避免通过源码分发方式的模板代码在不同的编译单元产生外部可见的相同符号而造成重定义的链接错误。
外部参考
- Linkers and Loaders
- ISO/IEC 9899:1999
- Computer System: A Programmer’s Perspective,2e
- Linux多线程服务端编程:使用muduo C++网络库
更新日志
2017.04.11
- 优化部分措辞、修复标点错误
- 增加更多示例
2017.04.14
- 增加GCC工具链编译和链接参数
2017.04.16
- 优化部分措辞,增加更多示例介绍
- 引用C99标准中Translation environment的概念
- 增加“为什么声明要与定义分离?”
2017.04.17
- 增加更多
translation unit以及预处理器的介绍 - 修复部分可能会引起歧义的描述,举出更多示例使描述更精确
2017.07.01
- 增加
C++模板的链接部分

