在文章基于 ZSTD 字典的 Shader 压缩方案中,我介绍了一种利用ZSTD字典压缩UE的ShaderCode的方法,可以极大地提升ShaderLibrary的压缩比。但训练字典和使用字典进行压缩的流程仍然比较复杂,并不是一个高效的工程实现:
- 需关闭引擎默认的Shader压缩
- Cook一遍项目才能Dump每个Unique Shader的ShaderCode
- 基于Dump出的ShaderCode文件,使用ZSTD程序训练字典
- 再次执行完整的Cook过程,使用字典进行压缩,生成最终的shaderbytecode
根据上述的流程,需要变动引擎才能实现Dump ShaderCode;其次是流程的割裂,Dump ShaderCode之后需要拉起zstd程序执行训练才能得到字典;最后,仍需要再Cook一遍工程,使用训练出的字典压缩Shader。并且在关掉Shader的压缩后会导致使用LZ4压缩的DDC Cache Miss,重复Cook执行的时间开销巨大,在海量Shader的项目中耗时无法接受。
基于这种痛点,我研究并实现了一种高效的字典训练方法,无需修改引擎,并且十分快速地训练字典和基于字典压缩。能够直接从ushaderbytecode中训练字典,并生成使用ZSTD+字典压缩的ushaderbytecode,极大地提升了处理效率,完全Plugin-Only的实现,接入成本几乎为零,后续将作为HotPatcher的扩展模块发布。
基于前文的字典训练流程,问题的核心在于三点:
- 如何高效地获取未被压缩的ShaderCode
- 如何脱离对ZSTD程序的依赖,完全在UE内实现字典的训练,避免额外的IO过程
- 如何避免重新Cook的而仅用字典压缩ShaderCode
本篇文章的内容会依次通过分析并解决这三个问题展开。
DumpShaderCode
哪种Dump方式更合理?
如果高效地Dump ShaderCode,需要搞明白一个问题:在何处Dump最为合理?
- Shader编译完成时
![]()
FShaderCodeLibrary::AddShaderCode时(序列化ushaderbytecode)![]()
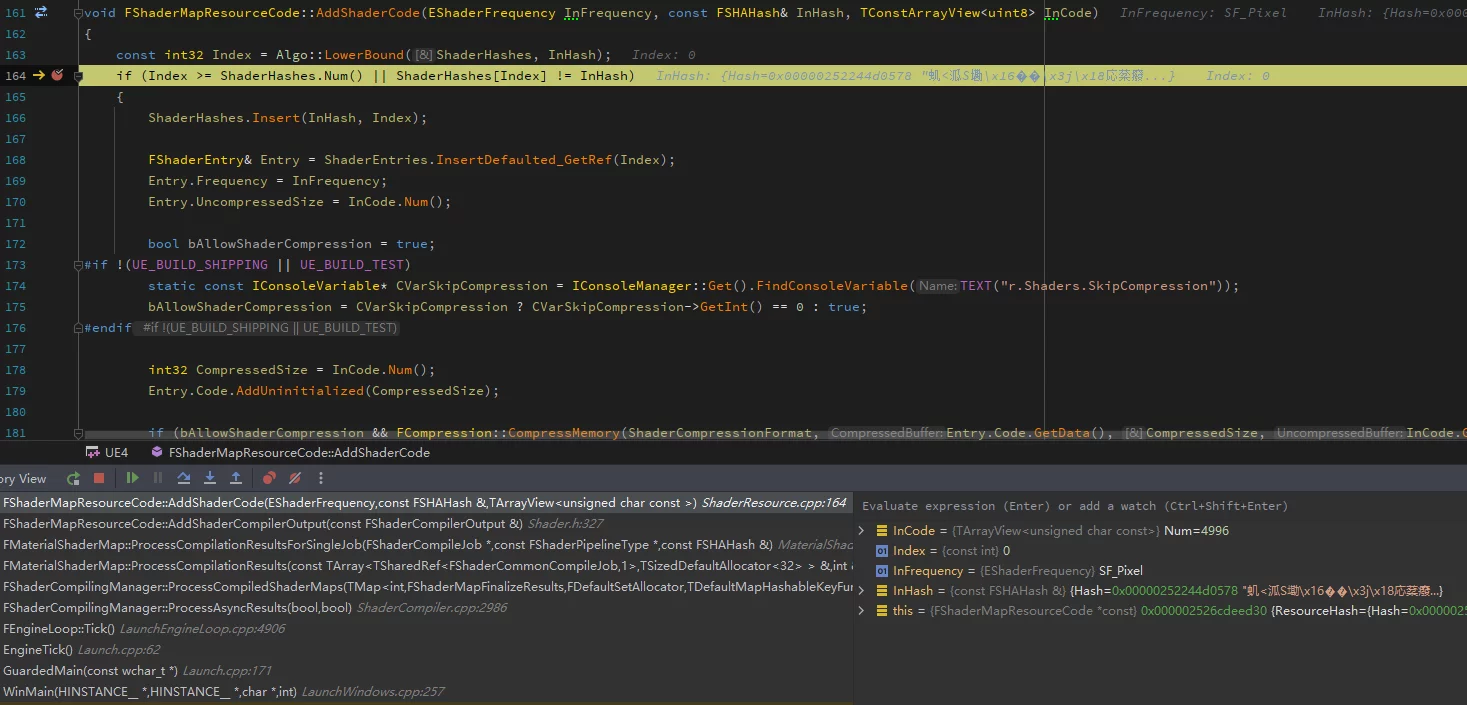
在基于 ZSTD 字典的 Shader 压缩方案中的思路是在FShaderCodeLibrary::AddShaderCode中,因为从DDC缓存的Shader不会再走编译流程,如果在Shader编译完成时,会漏掉DDC缓存的。
但这两种都不是最好的方案,其实认真思考一下就能发现,其实在最终打出来的包中,已经包含了当前平台的最终的所有ShaderCode:
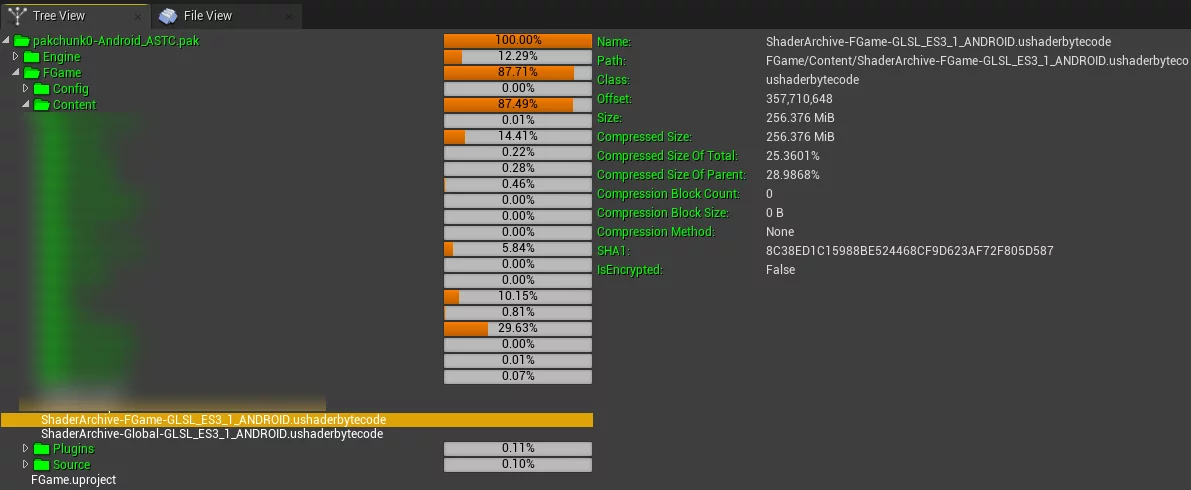
默认情况下,项目中的Global和ProjectName的这两个ushaderbytecode文件,就是项目中完整的ShaderLibrary,它们默认是经过了LZ4的压缩。
如果能够直接从默认打包生成的ushaderbytecode中提取出原始未压缩的ShaderCode,再进行训练,可以避免重复Cook的过程。
要实现这种方式,需要分析ushaderbytecode的文件格式。
ushaderbytecode格式分析
ushaderbytecode文件是UE的管理ShaderCode容器,用于存储shader hash和shadercode的对应关系,供运行时查询和加载。
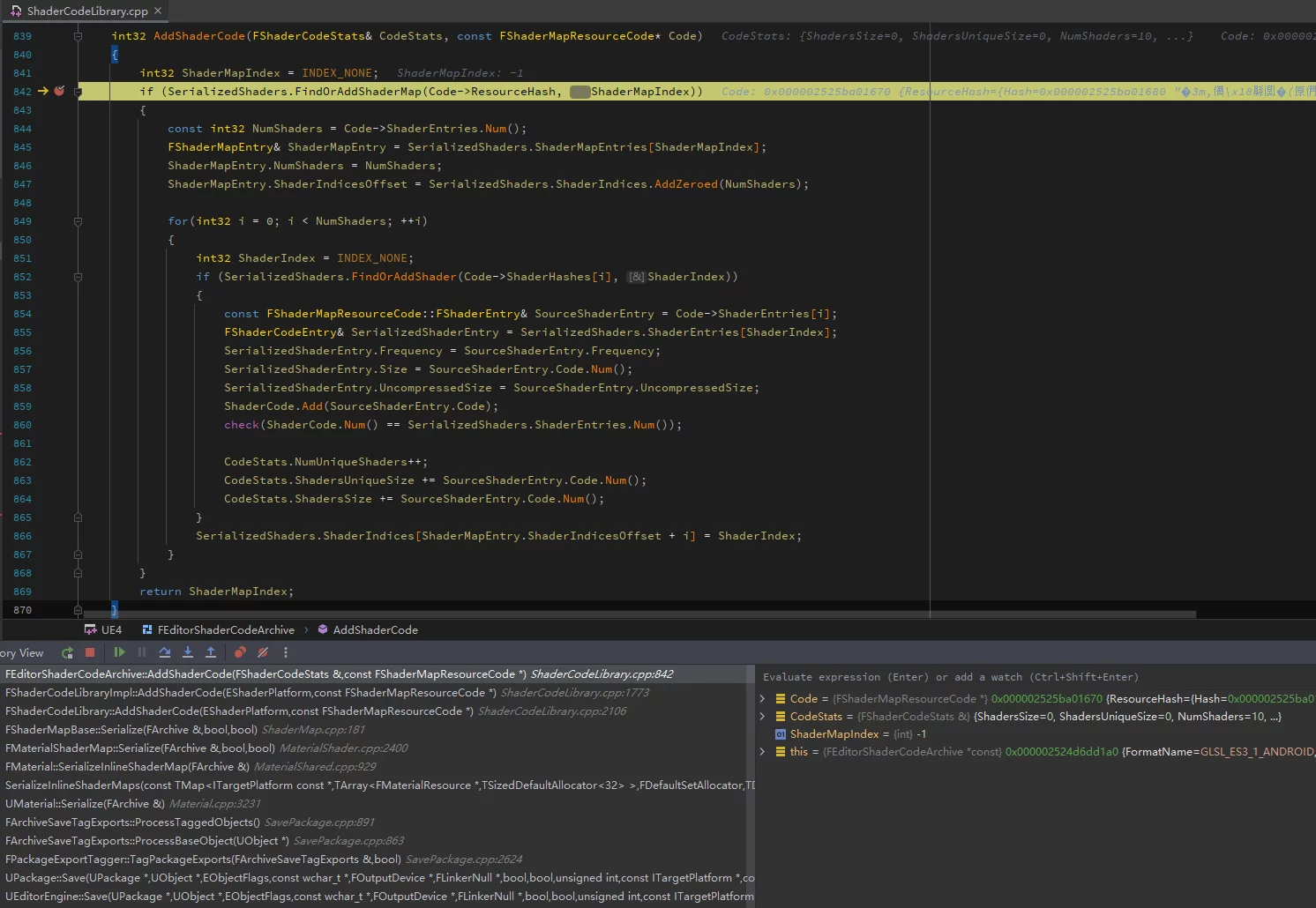
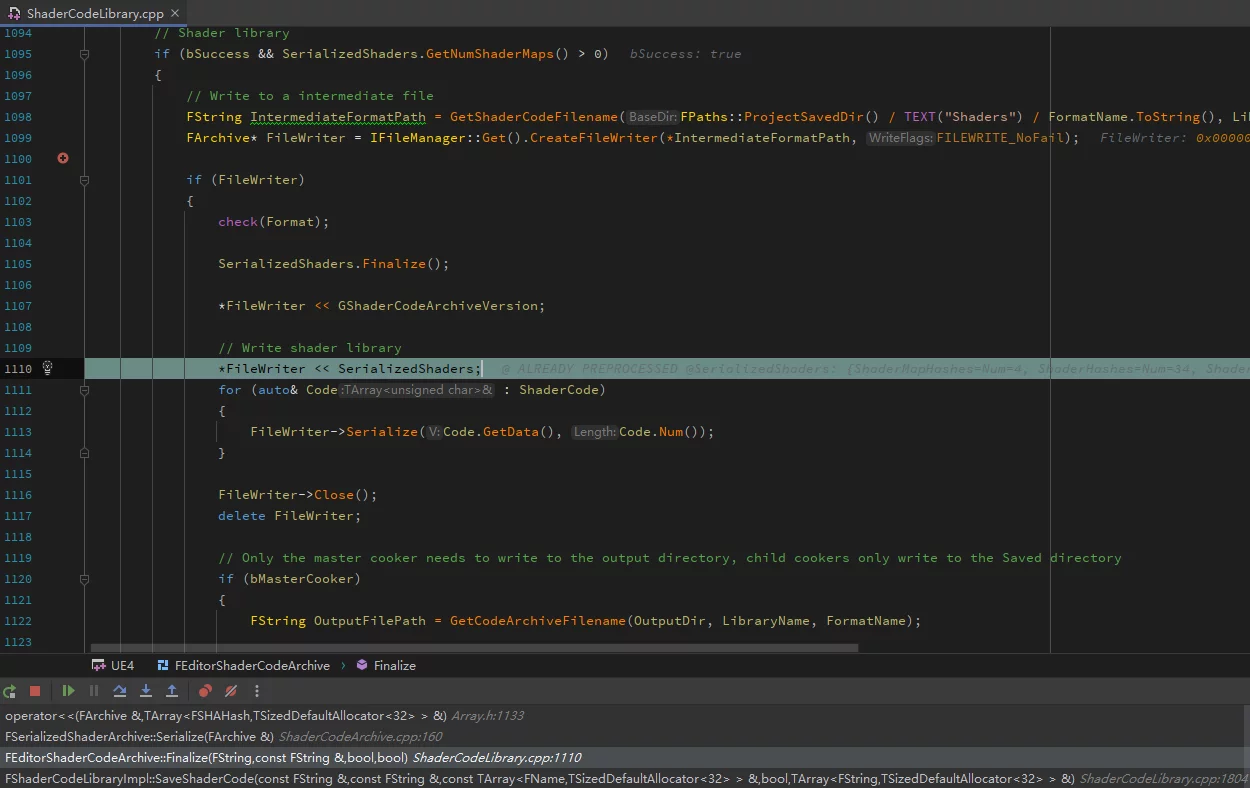
ushaderbytecode文件的序列化是在ShaderCodeLibrary中的FEditorShaderCodeArchive::Finalize中实现的。
最终的ushaderbytecode的文件格式:
unsigned int GShaderArchiveVersion=2;四字节,记录ShaderArchive的版本号FSerializedShaderArchive SerializedShaders;记录shader的Hash,偏移等信息,是ushaderbytecode的索引,用于记录当前shaderbytecode中包含的所有shader信息以及某个ShaderCode在文件中的偏移。
1 | class RENDERCORE_API FSerializedShaderArchive |

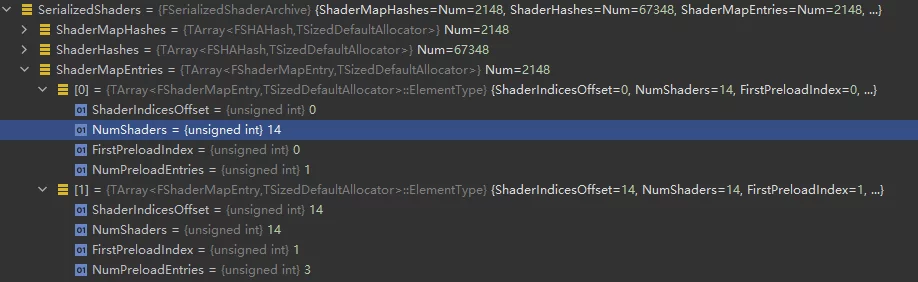
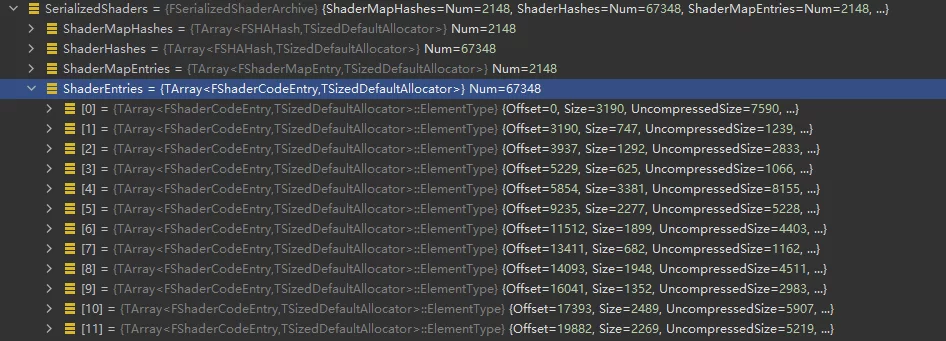
- ShaderCode数组,真正编译好的ShaderCode,按照顺序逐个序列化。
在运行时FShaderCodeLibrary中通过OpenLibrary加载一个ushaderbytecode时,并不会完整地把文件加载到内存里,而是只序列化了GShaderArchiveVersion和FSerializedShaderArchive结构:
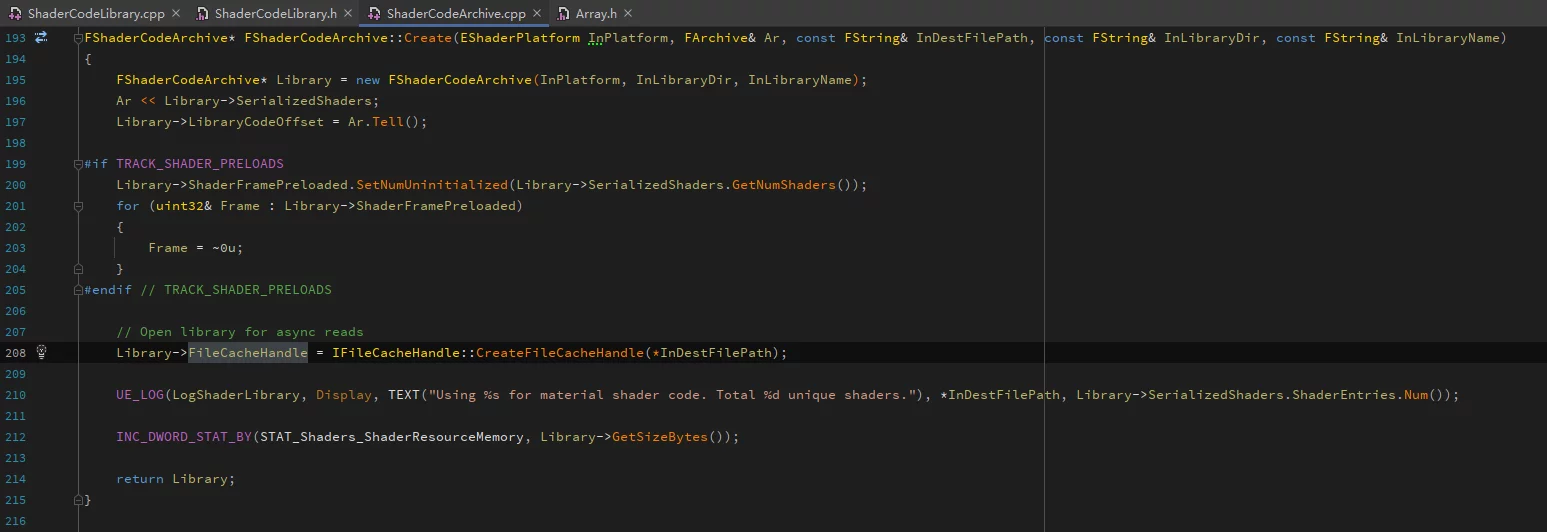
获取了ushaderbytecode的索引结构、版本号、以及文件句柄(FileCacheHandle),用于真实的ShaderCode加载。
一些概念的必要解释:
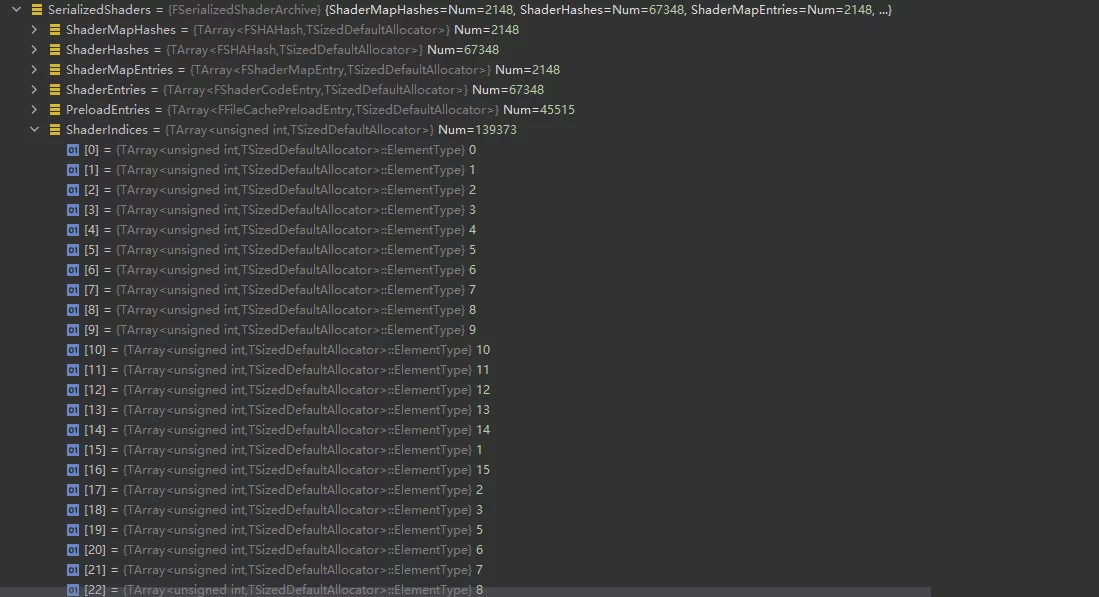
- ShaderMap包含多个ShaderCode,如一个Material会产生多个Shader变体,它们都位于同一个ShaderMap中。
- 多个ShaderMap中的ShaderCode会复用,可以具有交叉引用关系,但并不会真的拷贝两份。ShaderMap的Shaders通过
ShaderIndices记录,它只是下标,真正的ShaderCode的偏移存储在ShaderEntries中,被称作Unique Shader。 - Material在序列化时(开启bShareCode),会将ShaderMap的HASH序列化到uasset之中,便于在运行时去查询对应的ShaderMap。
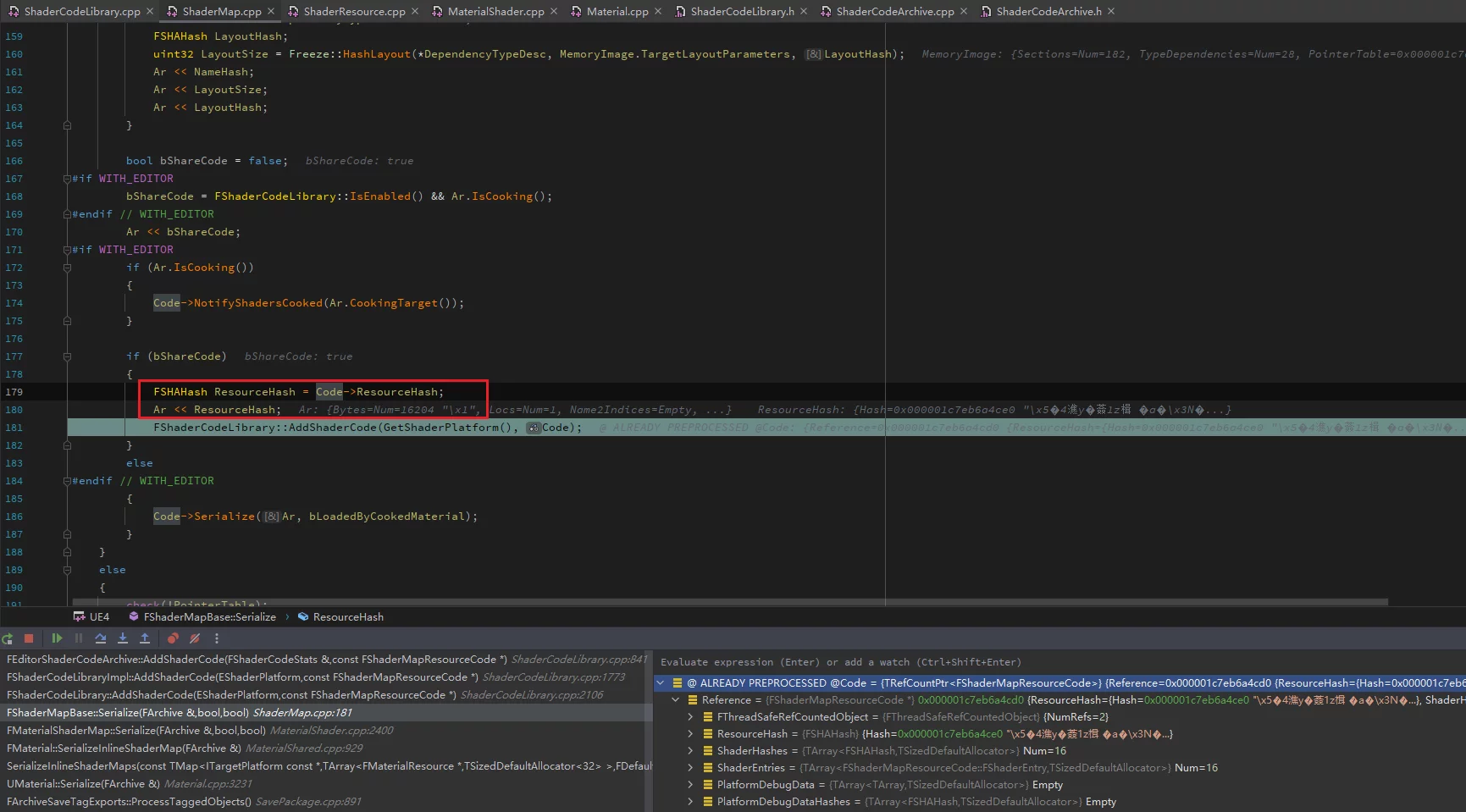
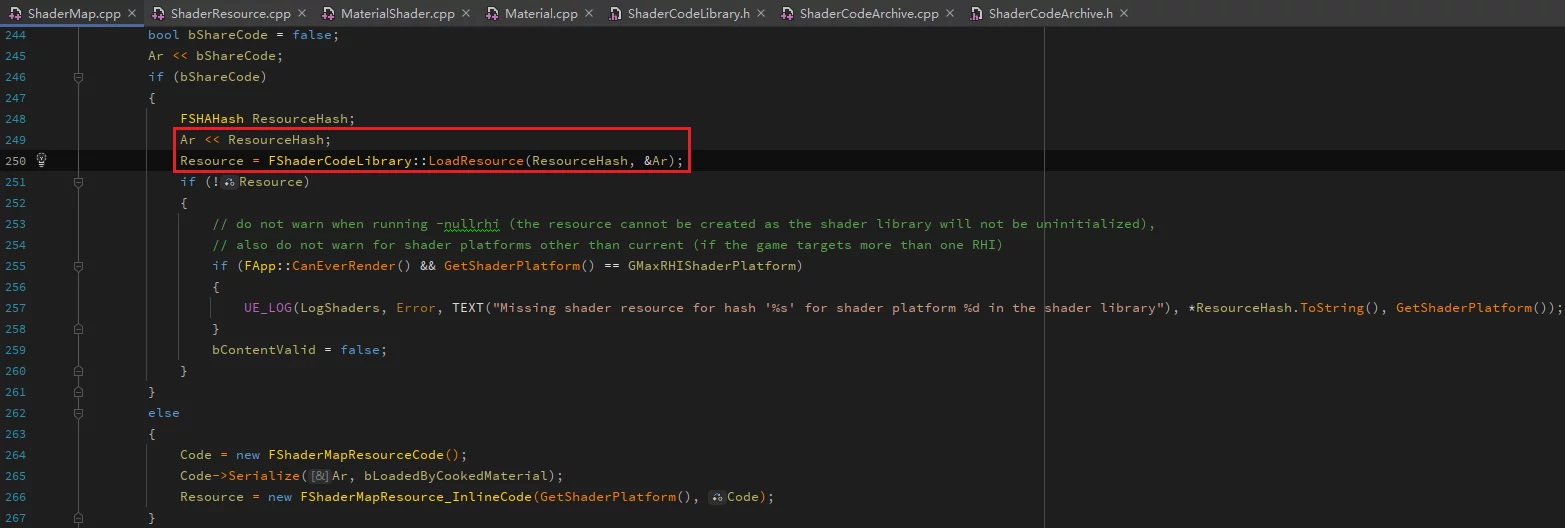
在读取时通过这个FSHAHash值,通过FShaderCodeLibrary::LoadResource加载:
读取ShaderCode
通过前面的分析,可以知道ShaderCode在ushaderbytecode中的存储结构。
FShaderCodeArchive中有函数ReadShaderCode,可以指定加载某一个ShaderCode: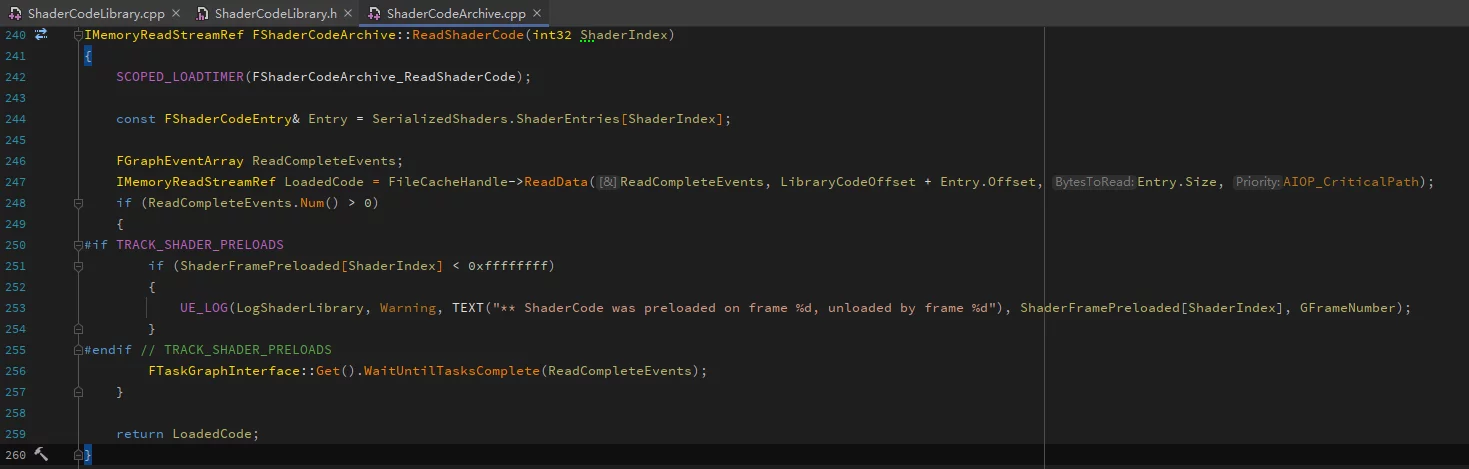
ShaderIndex可以通过ShaderHash通过以下接口获取:
1 | int32 FSerializedShaderArchive::FindShader(const FSHAHash& Hash) const; |
ShaderIndex其实就是对应的ShaderCode在ShaderEntries中的下标。
遍历某个ushaderbytecode中所有的Shader:
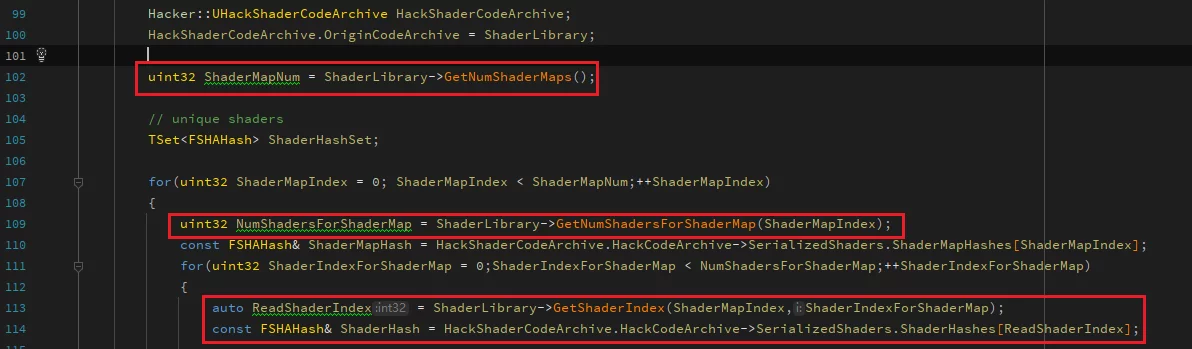
拿到了ShaderHash或者ShaderIndex都可以直接使用ReadShaderCode读取到所关联的ShaderCode数据:
1 | IMemoryReadStreamRef Code = Library->ReadShaderCode(ReadShaderIndex); |
但它默认还是经过LZ4压缩之后的数据,此时需要通过LZ4将其解压:
1 | FMemStackBase& MemStack = FMemStack::Get(); |
这样就直接从ushaderbytecoe中读取到了原始未被压缩的ShaderCode。
不管是将它们单独存盘也好、或者基于MemeryBuffer去训练字典也好,都可以。当然,建议的做法是把解压后的ShaderCode单独拷贝到一个MemeryBuffer中,供后面训练数据集之用,这样就无需IO,直接从内存中训练字典。
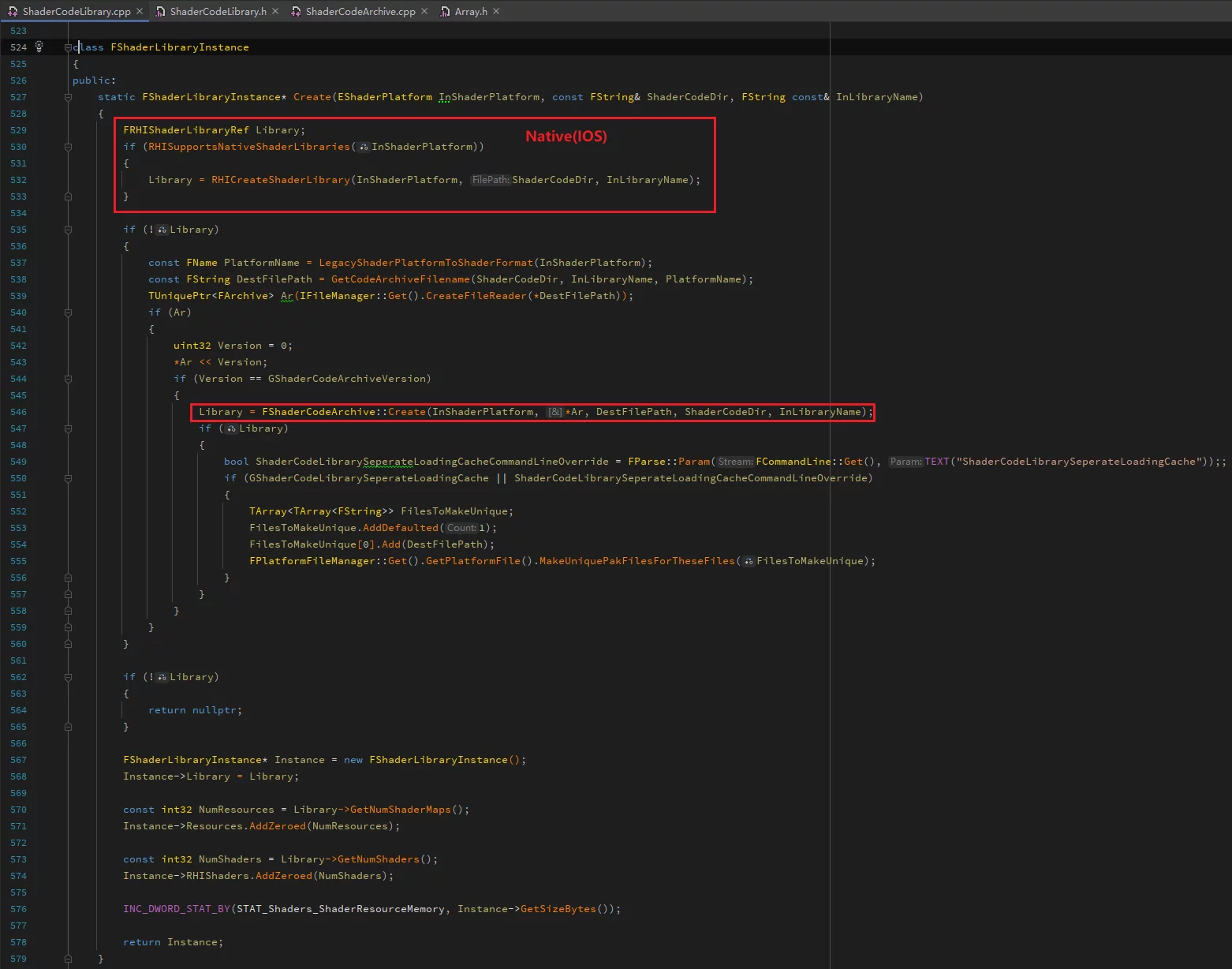
非变动引擎的实现
上一小结中介绍了从ushaderbytecode中读取ShaderCode的方法,但其实有一个问题:FShaderCodeArchive这个类未被导出。
1 | class FShaderCodeArchive : public FRHIShaderLibrary{// ...} |
在外部的模块中,无法访问它的成员函数,否则会产生链接错误。
而且ReadShaderCode这个函数,也是它的protected成员,无法被外部符号访问。
如果要变动引擎,最简单的修改,就是给他加上RENDERCODE_API,导出符号。否则,就要使用一些奇技淫巧来实现,这部分内容可以参考我之前的文章:
根据文章中的内容就可实现在不变动引擎的基础上,读取到ShaderCode,从而在公版引擎中也可以使用。具体方法本文不再赘述。
UE中训练字典
在上篇文章中,使用的是zstd的命令行程序进行训练的:
1 | # 创建字典 |
基于上一节中的所能获取到的ShaderCode的MemeryBuffer,可以直接从内存中训练字典。
直接在UE中使用ZSTD中的代码:
1 | ZDICTLIB_API size_t ZDICT_trainFromBuffer(void* dictBuffer, size_t dictBufferCapacity, |
可以封装一个辅助函数来创建字典:
1 | static buffer_t FUZ_createDictionary(const void* src, size_t srcSize, size_t blockSize, size_t requestedDictSize) |
这样能够避免把ShaderCode存盘,再调用ZSTD命令行训练的过程。基于内存中的数据,把训练逻辑都在代码中执行完。
字典压缩shaderbytecode
基于前面的两节的内容,已经能够直接从ushaderbytecode中训练出Shader的ZSTD字典。
那么基于ZSTD字典压缩生成最终的ushaderbytecode的最佳实践是什么呢?
通过ushaderbytecode格式分析一节的内容,可以知道ushaderbytecode的存储格式是这样的:
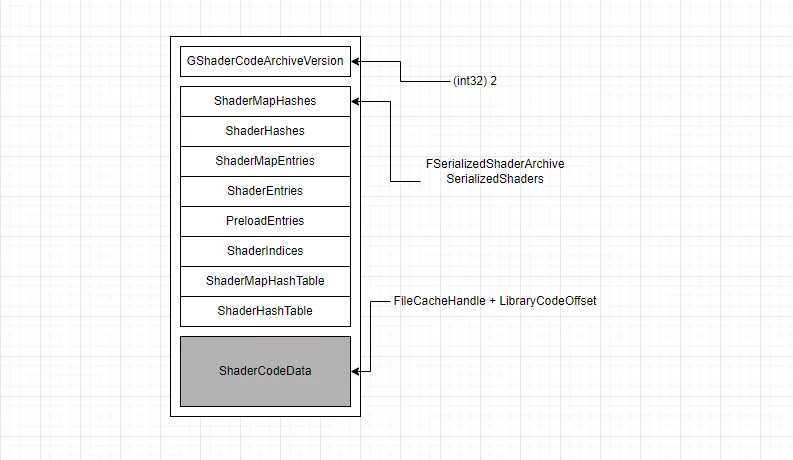
当要真的加载一个Shader时,会通过ShaderHash确定ShaderIndices中的下标,访问到ShaderHash对应的ShaderEntries[index],而ShaderEntries[index]里的内容,则是ShaderCode在上图ShaderCodeData中的offset、Size、UncompressedSize,实现ShaderCode的确定性读取。
如果想要直接基于原始的ushaderbytecode,通过字典压缩生成另一个最终的ushaderbytecode,主要修改以下两个部分:
- 字典压缩后的ShaderCodeData数据
- 修正字典压缩后的
ShaderEntries中每一个Shader的offset、Size(压缩后大小)
具体的实现步骤为:
- 读取原始的ushaderbytecode,保存
SerializedShaders - 按照顺序读取出每一个ShaderCode,并使用LZ4解压
- 使用ZSTD+字典压缩每个ShaderCode,追加到一个全局MemeryBuffer中,能够获得压缩后的ShaderCode的在这个MemeryBuffer中的Offset、Size
- 将每个ShaderCode的在MemeryBuffer中新的Offset、Size更新到前面保存的
SerializedShaders中 - 最后,依次将
GShaderCodeArchiveVersion、SerializedShaders、MemeryBuffer序列化到文件中
这样就直接从默认打包的ushaderbytecode中,生成使用字典压缩的ushaderbytecode,避免了额外的Cook流程。
ZSTD优化策略
升级至ZSTD的最新版本(1.5.2),相较于之前的集成(1.4.4),压缩率进一步提升。
接口层面的优化,使用*usingCDict替代*usingDict:
1 | // 推荐 |
因为*usingDict系列的函数会加载字典,只推荐在单次压缩中,对于使用同一份字典进行频繁压缩的场景会非常慢(慢一个数量级),所以要使用*usingCDict替代。解压也同理。
字典训练和压缩效率
测试数据:
- Shaderbytecode 256M
- 原始ShaderCode总大小(LZ4解压后):682M
- 66579 Unique Shaders
字典的训练:
Shader的压缩:
绝大部分ShaderCode的压缩耗时在1ms左右,根据ShdaerCode的大小浮动。
字典的训练+最终ushaderbytecode的生成,总时间不足4分钟,耗时完全不是瓶颈了。
LZ4压缩的ushaderbytecode和ZSTD+字典压缩再实际项目中的大小对比:
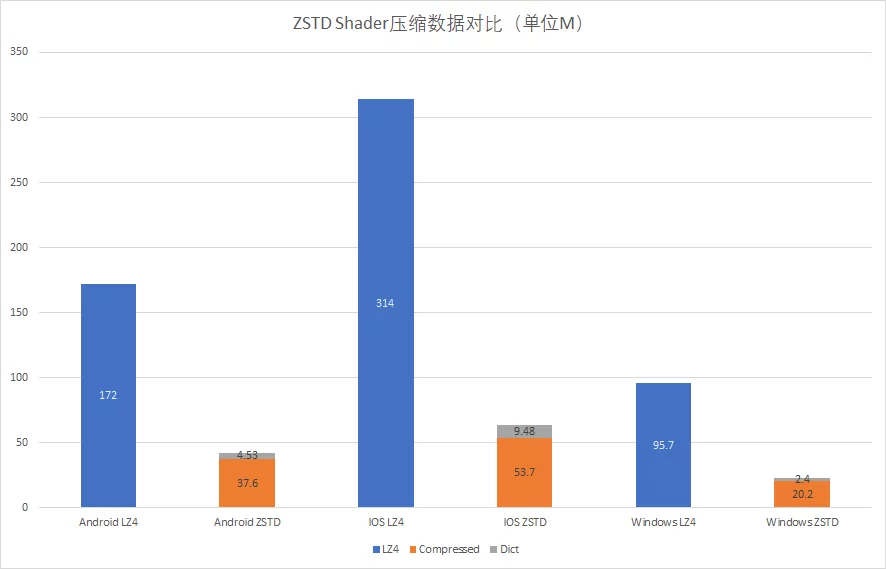
运行时案例
我提供了一个打包之后的运行时Demo,默认包是通过LZ4压缩的Shader,我提供了一个包含了字典、字典压缩之后的shaderbytecode(包含StarterContent与Global),可以用来验证功能和测试运行时效率。
下载地址:ZstdExample_WindowsNoEditor
将ZstdShader_WindowsNoEditor_001_P.pak放到Content/Paks下就会默认使用ZSTD与字典的模式读取使用字典压缩的ShaderLibrary:
不放这个Pak则使用引擎默认使用LZ4压缩的ushaderbytecode。
使用ZSTD模式的运行效果,可以看到没有Shader错误:
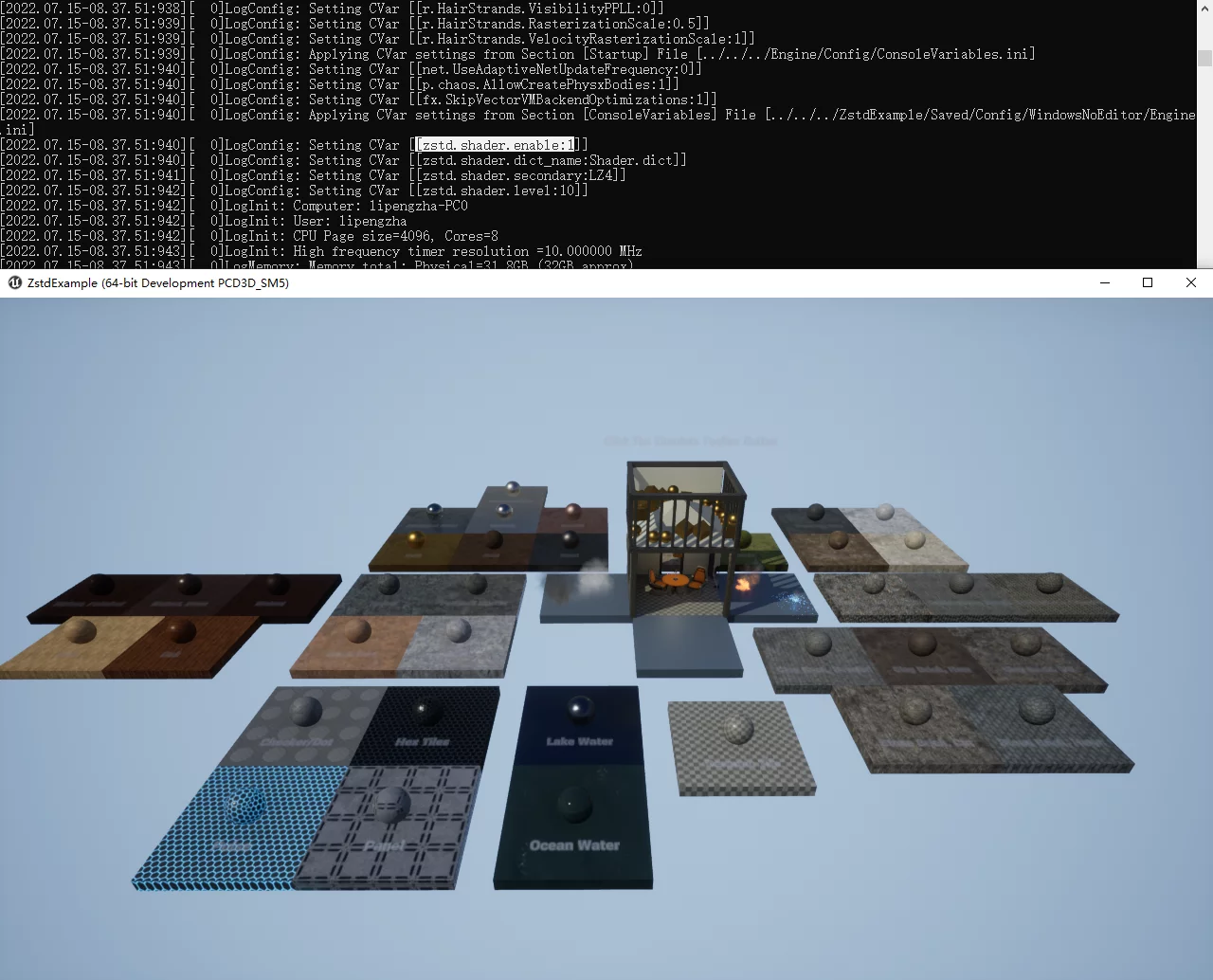
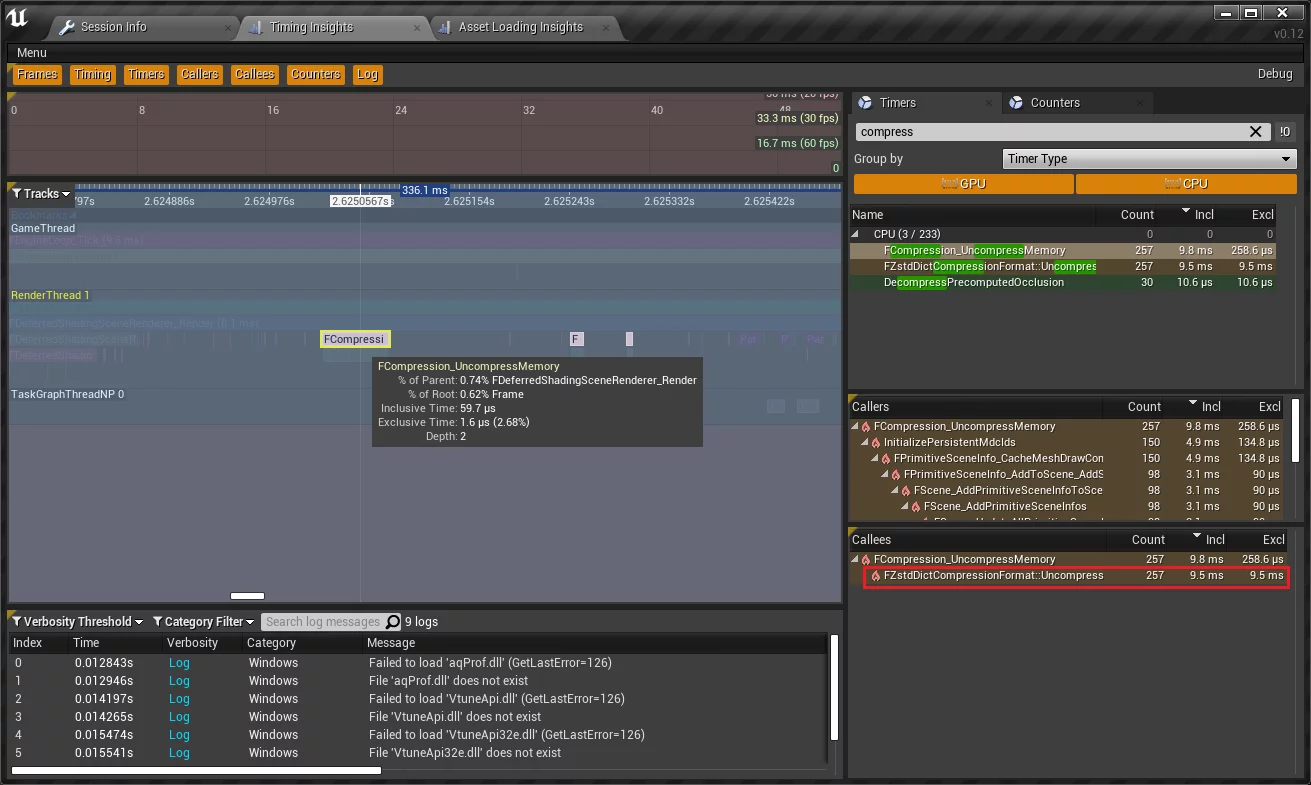
并且可以通过Unreal Insight分析运行时性能:
1 | ZstdExample -windowed -resx=1280 -resy=720 -log -trace=cpu -tracehost=127.0.0.1 |
HotPatcher集成
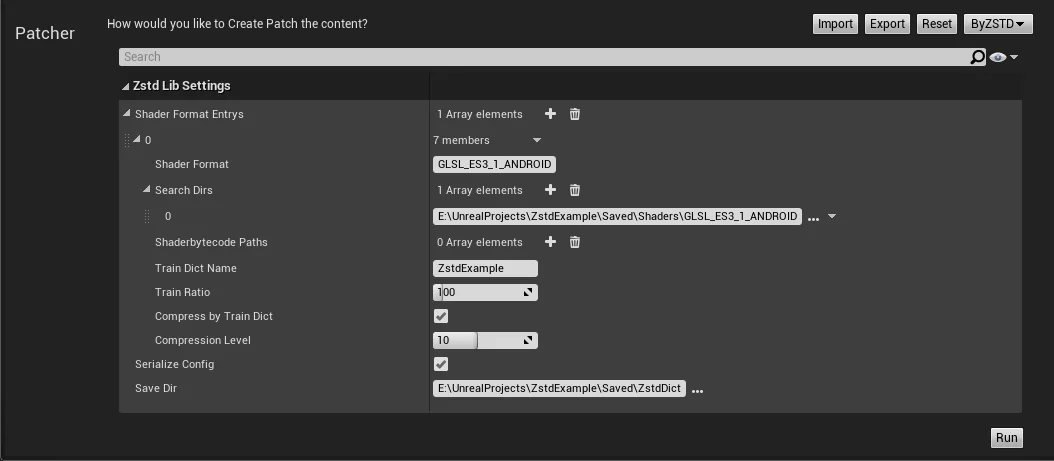
可以直接基于ushaderbytecode训练出字典,并用字典压缩已有的ushaderbytecode,最大限度地降低操作成本。
结语
本篇文章分享了一种高效的ZSTD Shader字典训练方法,通过分析ushaderbytecode的文件格式以及Dump ShaderCode的方式对比,直接在UE中训练字典。并分享了无需修改引擎的方法,可以无缝的使用在公版引擎中,降低对引擎变动的管理成本。
在一次调用过程中就可以实现训练字典以及利用字典进行压缩,极大地提升了压缩效率。从而可以将训练字典和利用字典压缩变成完全Plugin-Only的实现,无需额外的修改和流程,为集成至HotPatcher扫清理障碍,后续会作为HotPatcher的扩展模块发布。

