随着项目规模的日益增大,UE里Shader的变体数量逐渐累增,往往能够达到数百万的Shader变体,虽然UE为了避免Shader的重复存储提供了Share Material Shader Code功能,可以把Shader序列化到一个独立的ushaderbytecode文件中,但也会占用几百M的包体大小。而UE默认情况下,把这些NotUAsset文件默认进Chunk0,即必须进基础包,对于移动端的基础包影响很大,几百M的空间,可以放很多资源了。
为了解决这个问题,只能从三个方面入手:
- 降低项目中的变体数量,Dump出项目中的Shader信息,分析哪些是不必要的;
- 拆分shaderbytecode,基础包中只包含必要的Shader,其余按需下载。但UE默认没有提供这样的机制,可以使用我开发的HotPatcher拆分基础包,生成多个shader lib,使用热更流程动态下载资源和所需的shaderbytecode。
- 使用压缩率更高的算法来对ShaderCode进行压缩,引擎中默认使用LZ4;
第一种方式需要TA和美术协同实现,想要有显著的提升较为困难。第二种方案详见之前的热更新系列文章(Unreal Engine#热更新)。本篇文章从第三种方式入手,为Shader实现了一种特殊的压缩方式,可以有效地降低shaderbytecode的大小,大幅度提升Shader的压缩比,并且可以与方案2结合使用,在拆分shaderbytecode的同时,大幅度提高压缩率。
Forward
在Project Settings-Project-Packaging中开启Share Material Shader Code:
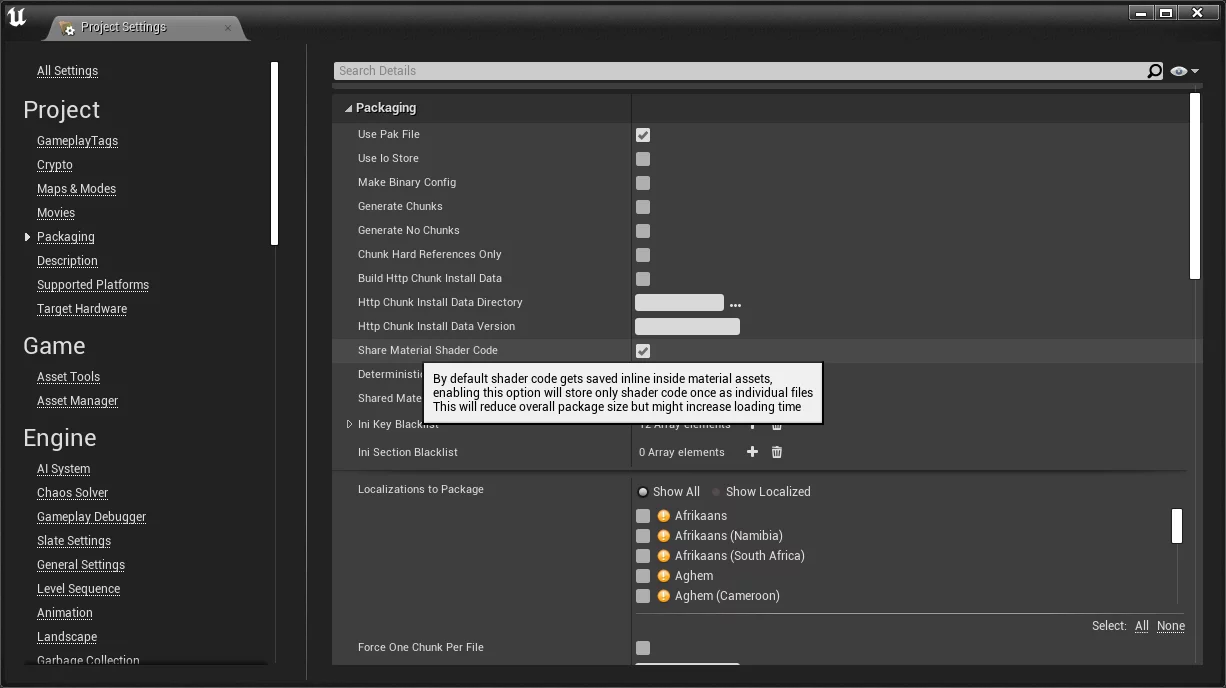
默认情况下,开启之后,UE会在Cooked的../../../PROJECT_NAME/Content下生成两个shaderbytecode(IOS编译为Native则是metalmap和metallib)文件:
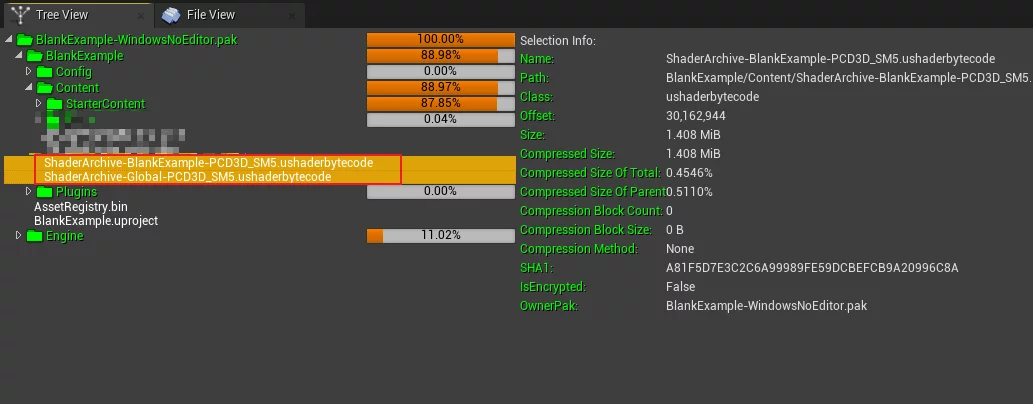
这两个文件存储着项目中所有的Shader。
而引擎也提供了默认的Shader压缩机制,使用LZ4,可以通过Console Variable控制开关:
1 | r.Shaders.SkipCompression=0 |
非0值则关闭压缩。
编译Shader完成后将Shader添加至ShaderMap时会执行压缩过程:
1 | void FShaderMapResourceCode::AddShaderCode(EShaderFrequency InFrequency, const FSHAHash& InHash, TConstArrayView<uint8> InCode) |
但是,就算使用LZ4压缩之后,Shaderbytecode的体积依然非常庞大(100w Shader体积达到91M):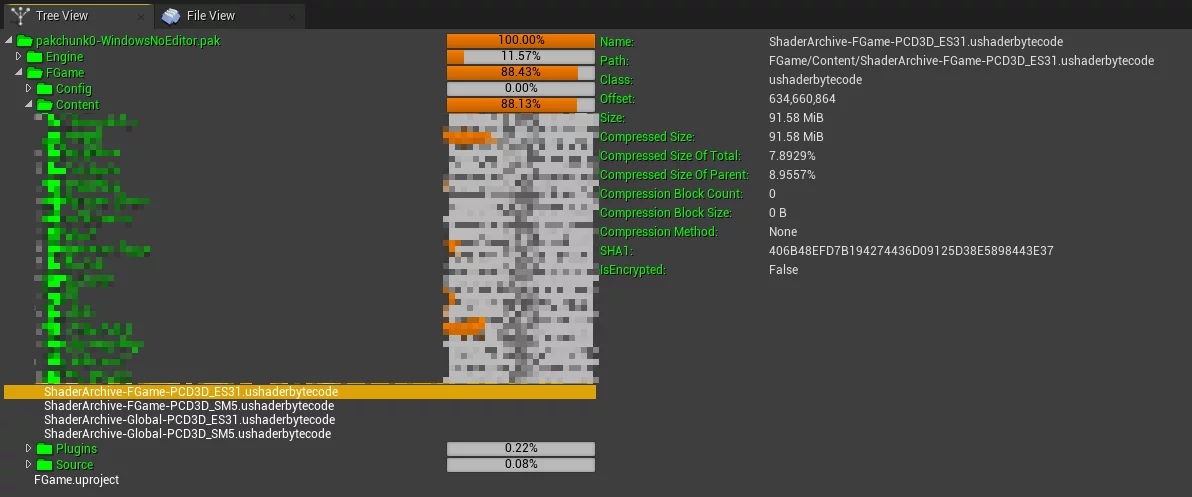
而且,如果目标平台支持多种Shader Format,如上图同时支持SM5和ES31,则体积还要翻倍。
ZSTD
在之前的博客文章中,我介绍过将ZSTD集成至UE中,用来作为PAK压缩算法,提升Pak的压缩比:
在游戏项目中,ZSTD的性能稍弱于RAD的Oodle算法,它也是被Epic收购后集成到UE里,用在4.27+的默认压缩算法。
每个ShaderCode的大小,大概在数k到100k之间,通常情况下,对于这种小数据的压缩难度很大,因为压缩算法是基于已有的数据来压缩未来的数据,小文件没有那么多的数据集,比较难提高压缩比。
但是ZSTD有特殊的压缩模式:从已有的数据中训练字典,用字典来压缩小数据。这种情况非常适合用于Shader这种小数据的压缩。
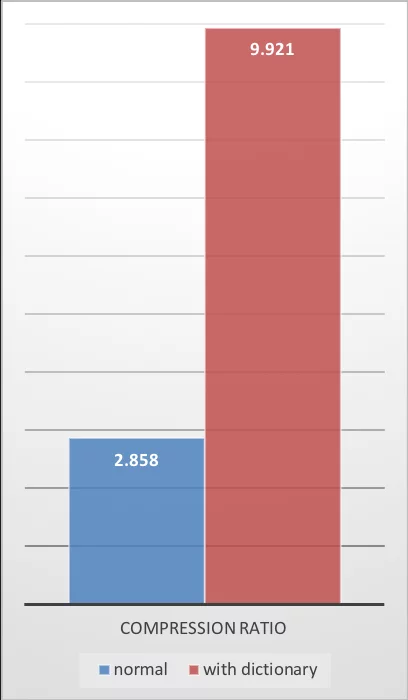
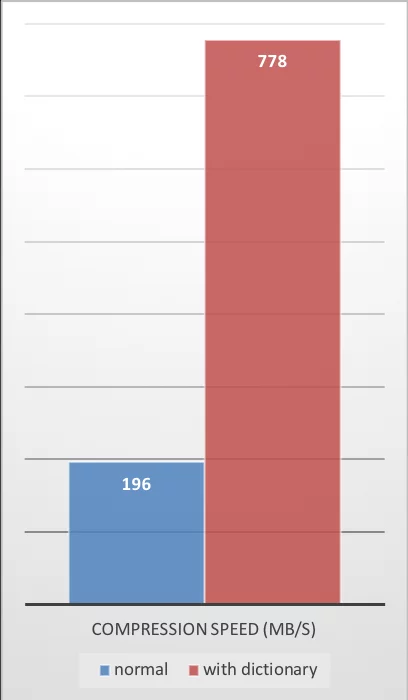
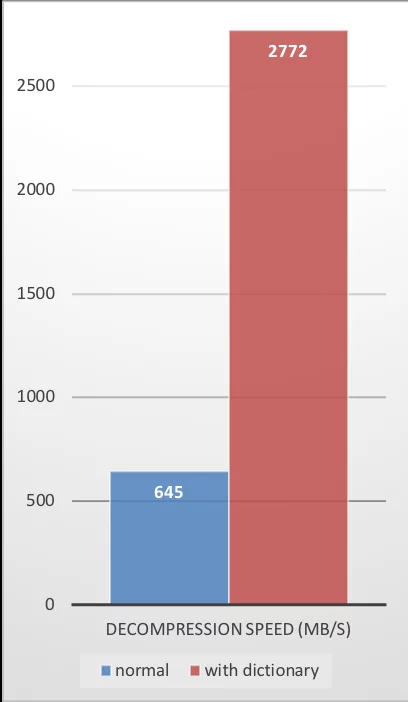
ZSTD提供的性能数据也非常好:
| Compression Ratio | Compression Speed | Decompression Speed |
|---|---|---|
 |
 |
 |
ZSTD提供的创建训练集和压缩、解压命令:
1 | # 创建字典 |
可以通过zstd --help查看更多的用法。
那么,如何把基于这种方式集成到UE中呢?
集成至UE
首先,前一节中已经介绍,基于字典的压缩方式,需要从已有的数据中训练出字典,在UE中,则需要基于未压缩的ShaderCode来训练。
20220718 Update:我提供了一种高效的字典训练方案,可以避免对引擎的修改以及重复Cook的过程。详见文章:一种高效的 ZSTD Shader 字典训练方案
集成流程大概需要这么几个步骤:
关闭引擎默认的Shader压缩在Shader的序列化过程中把所有的ShaderCode Dump出来使用ZSTD基于Dump出的Shader文件作为训练集创建字典将ZSTD集成至UE中,基于字典压缩ShaderCode将压缩后的ShaderCode序列化为ushaderbytecode同时需要修改引擎中从ushaderbytecode读取Shader的部分,确保ShaderCode能够被正确地解压
但是需要注意几点:
使用ZSTD通过训练集创建字典时,需要注意:
- 确保训练集足够大,训练集和字典的大小起码要保证10-100倍的比例,训练集越大,越能够保证字典的压缩效果
zstd默认的最大字典大小是110k,可以根据训练集的大小根据100倍的比例估算字典大小,通过--maxdict来指定- 一定要确保Dump出来的Shader数据是未经过压缩的
目前暂不开源具体的实现,上述的几点就是实现的核心步骤,运行时Shader加载正常:
压缩效果与性能
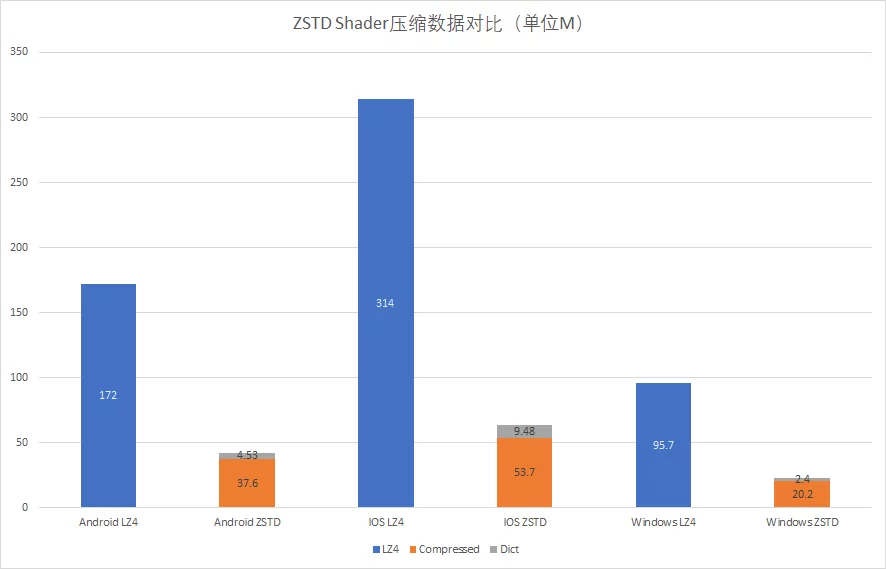
不同压缩算法对Shader的压缩数据:
| Android_ASTC | IOS | WindowsNoEditor | |
|---|---|---|---|
| LZ4 | 172 | 314 | 95.7 |
| ZSTD | 37.6 | 53.7 | 20.2 |
| Dict | 4.53 | 9.48 | 2.4 |
经过优化,使用ZSTD+字典的方式进行Shader压缩,相比引擎默认的LZ4提升了约65~80%的压缩率,效果非常之好。
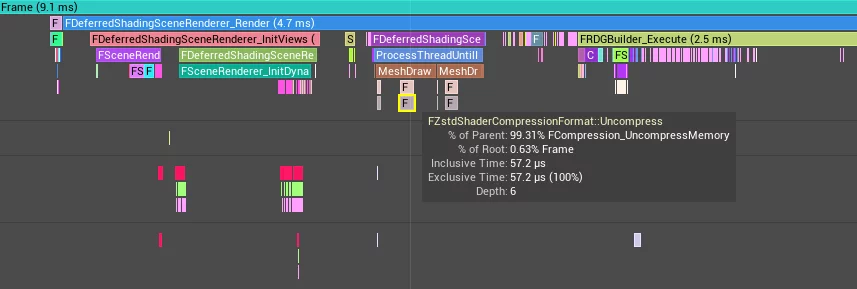
运行时的解压耗时:
结语
经过测试,基于ZSTD+字典的方式,相比LZ4,能够提升相当大的Shader压缩比,降低包内shaderbytecode的大小。
但仍需先Dump Shader进行手动训练出字典后,再进行压缩的流程,在UE原始的打包流程中,无法方便地介入这个过程实现自动化。未来的方向是实现打包及优化全流程的自动化,基于HotPatcher的框架可以方便地实现介入Shader的序列化过程,能够实现无感知地训练字典、以及将字典应用在Shader的压缩中,后续会在HotPatcher中集成该流程。

