Pak是UE中的UFS中的一环(Unreal File System),是在应用层构造的一种虚拟文件系统。用于把游戏相关的资源、文件打包至一个Pak文件中,避免在运行时对游戏资源的访问创建出大量的文件句柄,并且可以做读缓存(PakCache),提升加载效率。
并且,在UFS中,可以控制每个Pak的优先级,可以用来控制文件系统中文件的优先级。在通过UFS加载文件时,优先级高的Pak中的文件会被首先命中,就可以替换掉低优先级的文件,这也是UE实现热更新的关键,详见之前的热更新系列文章。
但默认情况下,Pak的打包都是在UE端进行的,PakUtilities和UnrealPak都是开发端的功能,运行时不存在,这意味着不能在运行时创建出Pak文件。但Pak本身是Archive的文件形式,理论上是可以进行运行时重组的。
本篇文章就从Pak的创建、文件格式、UFS分析、运行时重组可行性等方面着手,探讨运行时重组Pak的实现细节以及应用方向。
UFS的文件访问
从Pak中加载文件,可以通过控制挂载Pak的优先级,来控制哪些Pak中的文件是最新的。
1 | /** |
Create Pak
通常情况下,在UE中创建Pak文件,是通过PakUtilities中的ExecuteUnrealPak实现的,UE将其封装为了一个独立的命令行程序UnrealPak,可以将想要打包的文件通过一个ResponseFile描述文件创建出来。
ResponseFile文件格式:
1 | # 绝对路径 相对路径 参数 |
每个文件一行,分别为文件的绝对路径、UFS中的虚拟路径、参数(压缩等)。
UnrealPak创建命令:
1 | # Engine\Binaries\Win64\UnrealPak.exe GENERATE_PAK_FILE.pak -create=RESPONSE_FILE.txt OTHER_ARGS |
UE的原始打包过程中执行的就是这一过程,把项目中的Cooked的文件、ini、Slate的图片资源等等文件打包进Pak内。
Pak Formats
Pak的文件布局
以创建Pak的过程,分析Pak的文件格式为例:将一个文本内容为ABC的文件ABC.txt打包成Pak文件。
其Pak文件的二进制布局如下:
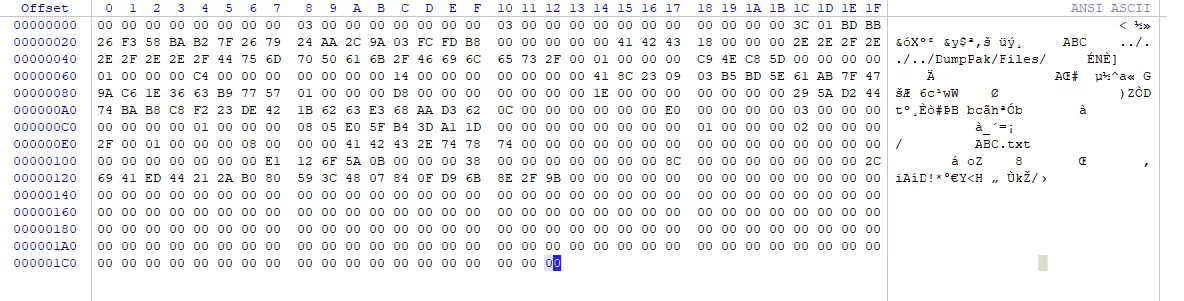
通过分析代码,Pak的布局信息如下:
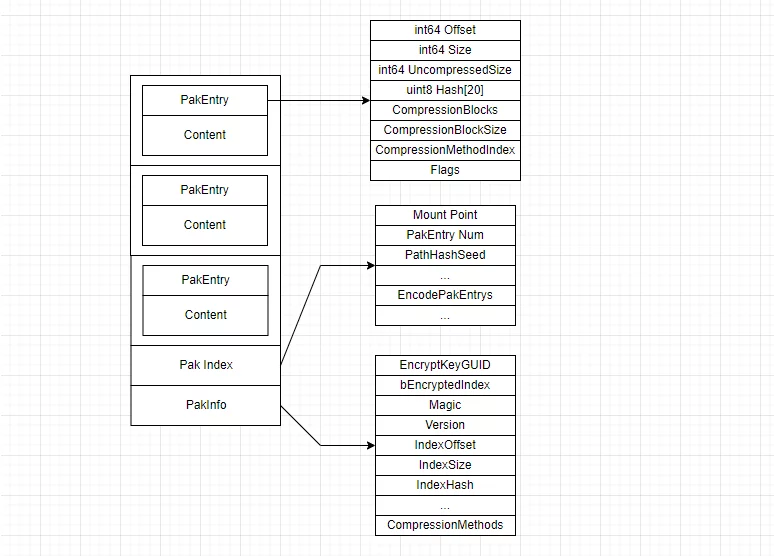
对应到上面打包出来的Pak文件,分成以下四部分:
PakEntry(文件的描述信息):
PakEntryContent(文件内容):
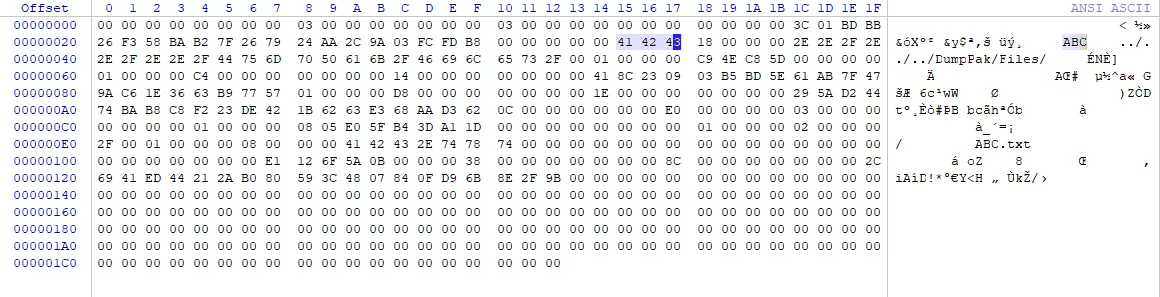
PakIndex(Pak文件描述区):
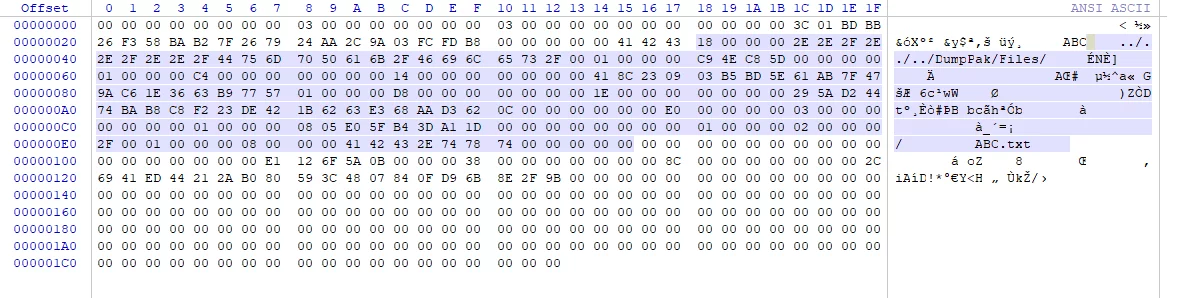
PakInfo(Pak信息区):
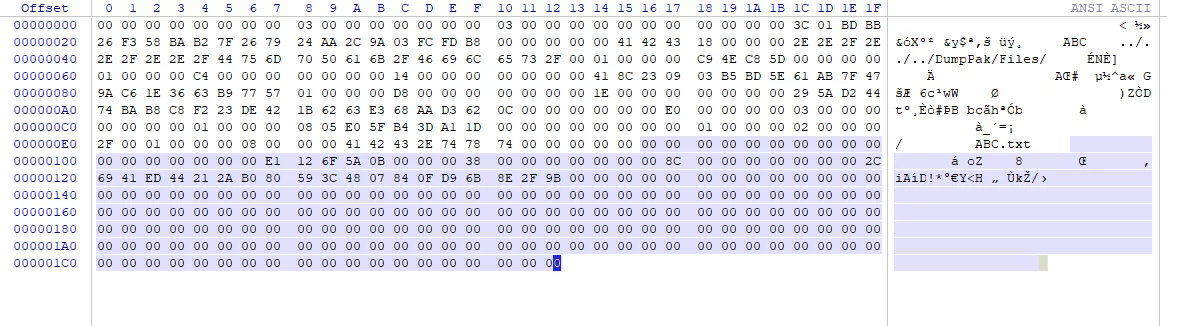
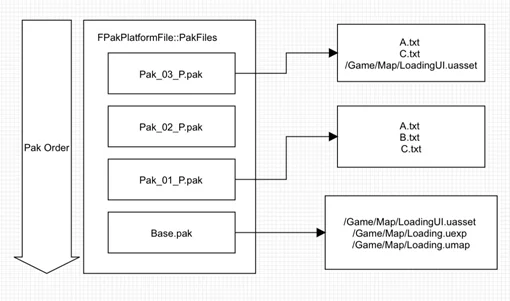
Pak的挂载分析
当引擎挂载Pak时,会从Pak文件末尾读取PakInfo,确定Pak的版本信息,并且读取Pak中的PakIndex在文件中的偏移、大小、Hash值,用于读取Pak中文件的基本信息。
当获取到PakIndex偏移和大小之后,如果项目中开启了bEncryptIndex,会把Pak中的整个PakIndex部分信息加密,在运行时需要解密之后才能访问。
当获取到PakIndex之后,能够获取到当前Pak的MountPoint、文件数量、 每个文件的文件名以及在Pak中的偏移(注意这个偏移值是包含PakEntry的)。
在之前的文章中,已经提到过Pak的MountPoint的作用:Mount Point 的作用
MountPoint是Pak中所有文件的公共目录,主要作用有两点:
- 降低文件路径的存储冗余,PakIndex中只存储文件相对与MountPoint路径
- 一种文件查找的加速方法,当从Pak中查找文件时,先检测要查找的文件是否存在于当前的Pak中。
如从UFS中查找一个文件:../../../FindExample/Content/Database.db,当查询到MountPoint为../../../FindExample/Content/Otahers的Pak时,通过简单的对比就可以知道要查找的文件不在当前Pak之内,而无需真的去Pak中查询。
当挂载Pak时,并不会真的去把Pak完整地加载到内存中去,而是通过读取PakInfo和PakIndex部分的信息,在UFS中建立一个虚拟的文件结构。只要当尝试去加载文件时,才会根据PakIndex中的信息,获取到PakEntry,去Pak文件中的指定偏移位置读取文件并通过正确的压缩算法来解压文件。
Create Pak at Runtime
前面分析了Pak的格式,以及UE在运行时挂载Pak和加载文件的流程,那么要回到文章开头介绍的部分:在运行时能够创建Pak文件吗?
答案是肯定的,Pak的文件格式就是一种典型的Archive格式,把一些文件、数据序列化到同一个文件中去。只要我们按照UE自己创建Pak的格式和读取流程进行序列化,就能创建出在运行时能够正常读取的Pak文件。
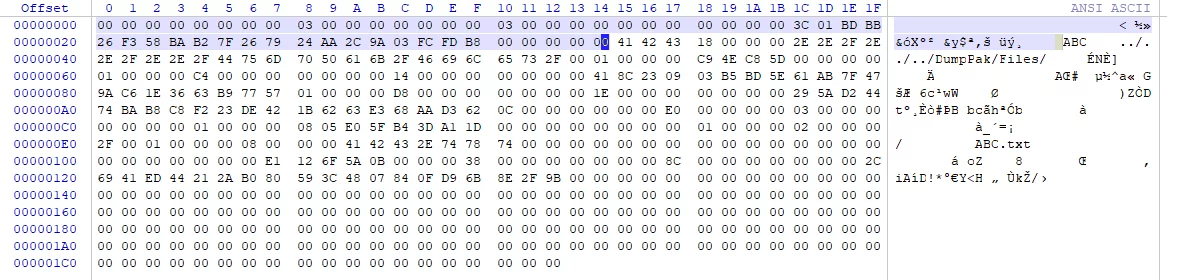
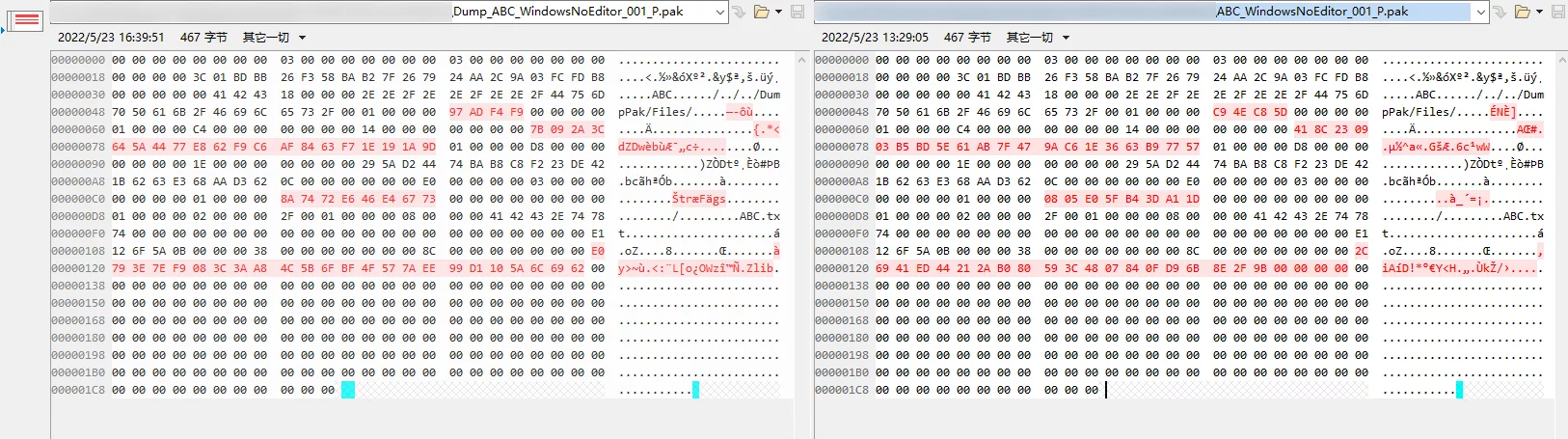
再回到UE的Pak文件格式这张图:
注意:上图中PakEntry中的Offset值总是0,这是一种保护机制,PakEntry的真实偏移是在
PakIndex中记录的,将PakEntry段的置为0,则避免了越过PakIndex直接去文件中读取的可能,因为PakIndex可以被加密,确保文件的读取行为是经过正确解密的。
以创建一个内容为ABC的文件ABC.txt为例,在运行时创建出一个Pak。
PakEntry
Pak中的每个文件都有一个PakEntry,用来描述当前文件,它的作用是:
- 从文件的哪里开启读取(Offset)
- 读取多少(Size,压缩后大小)
- 文件的原始大小(UncompressedSize)
- Pak中文件数据的Sha1值(压缩后数据)
- 每个压缩块的偏移位置
- 每个压缩块的大小
- 当前文件使用的压缩算法(PakInfo中的压缩算法下标,不压缩是0)
- Flags,有三种状态
Flag_None/Flag_Encrypted/Flag_Deleted
这些信息,我们可以给定任意一个文件就能够计算出来。
Content
当我们为一个文件构造出一个PakEntry之后,Content的内容就非常简单了,如果开启了压缩,就把压缩后的数据序列化,如果未压缩,则直接把整个文件序列化到Pak文件中。
PakIndex
Pak中的PakIndex,并不是一个完整的具有类型的数据结构,它是一种散列的数据,根据参数的不同可能产生不同的大小(如要序列化的Pak文件路径的Crc值,是否加密、是否序列化PathHash、DirectortyIndex等等)。
PakIndex在较新的引擎版本中提供了一个单独的函数:
1 | void FPakFile::EncodePakEntriesIntoIndex( |
可以根据PakUtilities中创建Pak的流程仿造PakIndex序列化的逻辑。
PakInfo
最终,Pak文件的末尾,就是FPakInfo的信息,它的结构定义如下:
1 | /** |
需要根据前面的PakIndex的序列化情况,把PakIndex的关键信息(Offset、Size、Hash、Encrypt等)存储,这样,在Mount Pak后,能够正确地访问到PakIndex,进而能够获取到Pak中每个文件元素的信息。
并且,它还提供了一个Serialize函数:
1 | void FPakInfo::Serialize(FArchive& Ar, int32 InVersion) |
InVersion可以传入FPakInfo::PakFile_Version_Latest:
1 | FPakInfo Info; |
最终把整个Archive序列化到文件即可,就创建出了最终可以用来在运行时访问的Pak文件。
因为创建Pak时,会在PakIndex中存储所创建Pak的路径的Crc32的值,所以它会影响Pak的二进制稳定性,如我们基于同一个文件创建出不同的Pak文件,其实Pak的内容是有差异的,但它们都可以正常使用和加载文件。
应用场景
在运行时创建Pak,以及它的意义,我思考了一些使用场景。
热更新
原先的更新,是逐Pak下载,远程打包了多少个Pak,就要把它们全部下载下来。
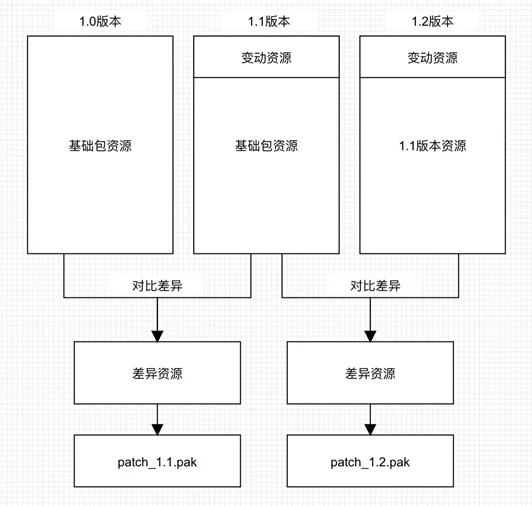
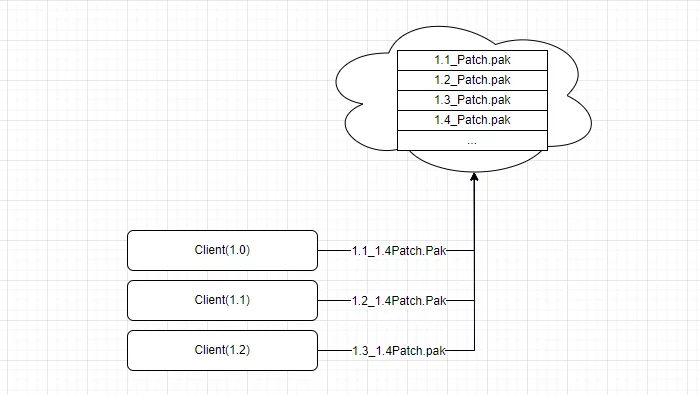
如果使用运行时Pak的方案,不管远程打包了多少个Pak,与本机差了多少个版本,都能一步下载,并且都存储在一个Pak中。
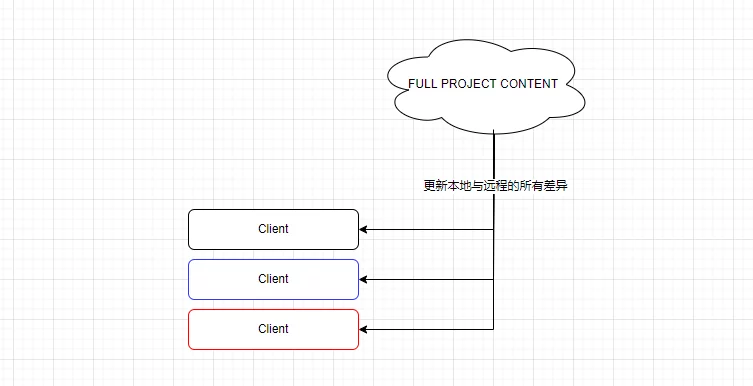
甚至可以实现无版本的更新:远程不做任何差异对比,只打包完整的工程。由客户端进行本地与远程的文件版本比对,确定哪些差异需要下载,可以极大地降低管理成本。

并且可以合并以及清理本地的已有Pak,降低Pak数量过多造成的Pak句柄过多、以及Pak数量造成的查询缓慢问题。
UGC
在Client端创建Pak,也可以用在是UGC的打包策略,玩家的自定义内容可以打包成Pak,并且能够再次分发。
结语
本篇文章研究了Pak的创建、加载过程以及对UFS的分析,验证了在运行时创建Pak的可行性,以及应用场景。本篇文章中的技术实现暂不开源,后面会将该功能作为HotPatcher的一个运行时Mod发布。

