在游戏项目中,当我们在打包各个平台时,总希望每个平台的包能够最小化便于分发,而且上架某些平台还有明确的大小要求。
对于UE而言,它包含了巨量代码以及大量的插件,Build阶段还将生成反射的胶水代码,在编译时产生了大量的代码段。以Android平台为例,将导致libUE4.so的大小急剧增长,对于包体和运行时内存都造成了压力。
再加上一些引擎必要和额外带入的资源也能占据上百M,空APK的大小很容易达到数百M的规模!不仅仅为了符合上架平台的要求,从包体和内存优化的角度,也有必要对UE包的大小进行裁剪。
本篇文章会以Android为例,从各个方面介绍UE包中的可裁剪部分的优化思路与实践,同时优化APK大小和Native库的运行时内存占用,其中的策略也可以复用在其他平台。
包大小分布
在APK内,游戏相关的空间占比较大的部分,为下面几项:
- 可执行代码(so -
lib/arm64-v8a) main.obb.png(游戏内资源Pak、DirectoriesToAlwaysStageAsNonUFS的部分)- 第三方组件拷贝进APK内的文件
需要分别针对上面列出的三种情况,分别制定具体的优化策略。
压缩NativeLibs
当APK安装时,对于NativeLibs有两种处理方式:
- 安装时解压so到应用的内部存储目录(
/data/app/<package_name>/lib/) - 直接从APK文件中加载so,可以加快安装过程
而它就引出了一个问题:如果允许安装时解压,则NativeLibs打包进APK内是可以被执行压缩的。
对比一下实际的压缩与否的大小情况,对APK大小的影响非常大:
| 压缩 | 不压缩 |
|---|---|
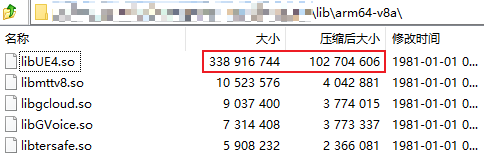 |
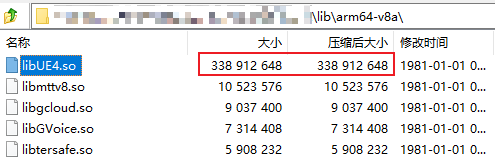 |
对于原生Android而言,是否在安装时解压NativeLibs是由AndroidManifest.xml中的extractNativeLibs控制的:
1 | <application android:allowBackup="true" android:appComponentFactory="android.support.v4.app.CoreComponentFactory" android:debuggable="true" android:extractNativeLibs="false" android:hardwareAccelerated="true" android:hasCode="true" android:icon="@drawable/icon" android:label="@string/app_name" android:name="com.epicgames.ue4.GameApplication" android:networkSecurityConfig="@xml/network_security_config" android:supportsRtl="true"> |
在新版引擎中,在AndroidRuntimeSettings配置中直接提供了bExtractNativeLibs的选项:
1 | bool bExtractNativeLibs = true; |
需要注意的是,如果是旧版本引擎(4.27及之前),升级了grable升级后(>4.2)后,gradle用useLegacyPackaging取代extractNativeLibs,Manifest里的extractNativeLibs默认是false的,所以会导致APK增大。
解决办法是可以在UPL中强制把值改了:
1 | <addAttribute tag="application" name="android:extractNativeLibs" value="true"/> |
注意:它只是控制让so打进APK时是否执行压缩,并不会实际减少so的大小!对于可执行程序的优化,需要继续下面的代码优化的部分。
代码体积优化
关于代码体积优化的部分,在Android平台,核心目标是要减少单个so的大小!并且尽可能地避免对运行时性能的影响。
对NativeLibs大小优化思路:
- 减少动态链接库的数量,剔除不必要的
- 减少库内部的符号、减少代码段大小
- 剔除调试信息
对于所有的so,都可以在编译/链接时应用这些优化策略。
但对于UE项目而言,我们能控制的通常也只有引擎和项目的代码,库的代码需要库的提供者优化。所以接下来的优化策略,只针对于libUE4.so/libUnreal.so。
减小libUE4.so
在打包时,因为需要执行完整的编译,并且UE在运行时默认是Monolithic的模式,所有的代码都被编译到了同一个可执行文件中。(之前的文章有详细介绍:UE插件与工具开发:基础概念)
UE基于UBT的编译过程封装,以及提供target.cs/build.cs中的配置参数,使我们能够在一定程度上对引擎和项目代码进行编译控制,达到我们优化so大小的目的。
对于UE项目而言,优化so的大小有以下几种思路:
- 禁用不必要模块
- 控制代码优化(控制inline/O3/0z)
- 禁用Module不必要异常处理
- 启用LTO
- 剔除不需要的导出符号
禁用模块
可以把引擎中内置的明确不需要使用的模块在target.cs中关闭:
1 | // disable modules |
同时,需要梳理项目中引入的不必要的运行时插件,减少参与编译的Module的数量,从而减少实际参与编译的代码。
关闭inline
inline是编译阶段对运行时的执行效率优化,将函数调用直接替换为函数代码,而不是常规的函数调用。可以减少函数调用的开销,理论上来说可以提高程序的执行效率。
但inline会增大.text段的大小,可以酌情关闭。
- 修改
target.cs:bUseInlining = false;(仅在IOS/Linux/Mac/Win有效) - 修改UBT,在Android编译时受
bUseInlining控制,添加-fno-inline-functions编译参数
1 | if (TargetInfo.Platform == UnrealTargetPlatform.Android) |
注意:关闭inline后,如果某些函数具有高频调用,会带来一些性能损失;在非高频情况下,inline与否的性能,这个需要结合项目的实际性能情况进行控制。在我的测试结果中,是否inline对帧率影响微乎其微。
关闭异常处理
有些模块中打开了C++异常处理,但是没有try/catch的使用:
1 | bEnableExceptions = false; |
可以关掉,能够减少so内的.eh_frame的大小。
使用O3/Oz编译
在target.cs中控制bCompileForSize的值,可以选择使用O3或Oz编译代码:
1 | // optimization level |
O3和Oz的区别:
-O3:性能优先,积极内联、循环展开-Oz:体积优先,避免内联、保持循环
可以根据项目实际的性能情况,选择使用哪种方式。
启用LTO
LTO是Link Time Optimization的简称,可以在链接时剔除死代码、优化跨模块的函数调用、内联等。
在引擎的build.cs中可以bAllowLTCG打开,LTCG是LTO的一种实现,但是它也只仅在IOS/Linux/Mac/Win有效(UE4.25)。
支持Android的话,同样也要修改UBT(AndroidToolChain.cs),给Android添加受bAllowLTCG参数控制,选择是否添加-flto=thin的编译参数,thin是缩减大小与优化耗时的综合版本。
1 | bAllowLTCG = true; // LTO |
剔除导出符号
在编译so时,除非特殊设置,所有的函数和变量都会被导出,用于被其他的so访问。
但在UE引擎内,只有极少数的接口,是明确被外部访问的(JNI相关的接口),所以libUE4.so的符号导出绝大部分是浪费的,剔除掉符号导出可以大幅降低so的大小和内存占用!
现代编译器提供了version-script的链接时控制机制,可以通过传入一个ldscript文件来控制链接时的符号行为。
需要在编译过程中先构造出一个ldscript文件,填入符号导出控制代码,然后在target.cs中,传递给Linker:
1 | string VersionScriptFile = GetVersionScriptFilename(); |
对于UE而言,需要允许导出的只有Java_*/ANativeActivity_onCreate/JNI_OnLoad这三类匹配符号,,其余的均可剔除。
优化数据
经过上面介绍的一系列对代码体积的优化,收益明显。
so压缩后大小
前面提到了,NativeLibs进APK是可以被压缩的,所以当我们减少了so的原始大小,也能够减少压缩后的大小。
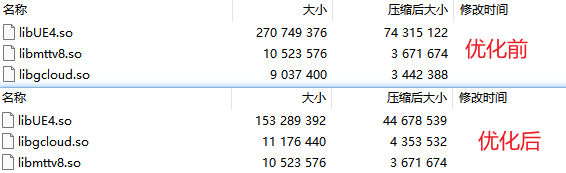
经过上面的优化之后,在Shipping的模式下,so的原始大小从原来的258M减少到了146M!
so的压缩后大小,从74.3M减少到了44.67M,减少了29.63M!可执行程序文件显著减小。
readelf优化前后对比(部分数据):
| arm64-v8a Shipping | 优化前 | 优化后 | 减少 |
|---|---|---|---|
| .text | 104.364 | 76.56 | 27.2 |
| .dynsym | 14.52 | 0.0185 | 14.5 |
| .gnu.version | 1.22 | 0.0016 | 1.22 |
| .gnu.hash | 4.02 | 0.00047 | 4.02 |
| .hash | 4.72 | 0.0063 | 4.71 |
| .dynstr | 50.0 | 0.0198 | 49.98 |
| .rodata | 11.13 | 6.35 | 4.78 |
| .rela.dyn | 24.76 | 22.79 | 1.97 |
| .got | 0.89 | 0.21 | 0.68 |
内存收益
对so大小的优化,同时减少了加载so的内存,也能够获得额外的内存收益。
安卓可以通过dumpsys meminfo来查看整个包的so占用内存情况,包含了所有已加载的so,但可以通过优化前后的差值得到实际的内存收益。
优化前:
1 | 127|PD2324:/ $ dumpsys meminfo com.xxx.yyy |
优化后:
1 | ** MEMINFO in pid 31482 [com.xxx.yyy] ** |
| arm64-v8a Shipping | 优化前 | 优化后 | 减少 |
|---|---|---|---|
| libUE4.so大小 | 246 | 145 | 101 |
| meminfo(so总内存) | 178.165 | 140.04 | 38.125 |
优化策略补充
重定位表压缩
SDK 28
在Android的MinSDKVersion大于等于28时(Android9),可以在编译和链接时开启RELR重定位表压缩。利用相对地址重定位的特点,对重定位信息进行高效编码,从而减少存储空间占用。
开启方法,需要在编译阶段给Compiler和Linker传递参数:
1 | AdditionalCompilerArguments += " -fPIC"; |
-Wl,--pack-dyn-relocs=android+relr,--use-android-relr-tags是 Android 特有的链接器选项,它们是对标准-Wl,-z,relro和-Wl,-z,now的补充和优化,特别是针对 Android 系统中动态链接和重定位的处理。 它们主要用于进一步减小二进制文件大小和改善加载时间。
验证是否生效,可以使用readelf -d libUE4.so,查看是否存在RELR字段: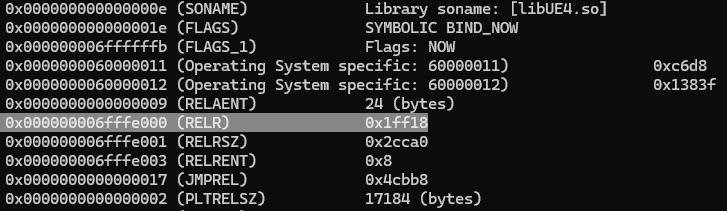
优化前重定位表的大小(25.82M):
1 | 8 .rela.dyn 0189c708 000000000000c720 000000000000c720 0000c720 2**3 |
优化后重定位表的大小(280K):
1 | 8 .rela.dyn 00013852 000000000000c6d8 000000000000c6d8 0000c6d8 2**3 |
优化后的重定位表大小从25.82M降低到280K,结果直接体现在so的大小减少了25M,使APK的大小也减少了4M左右,优化效果极为明显。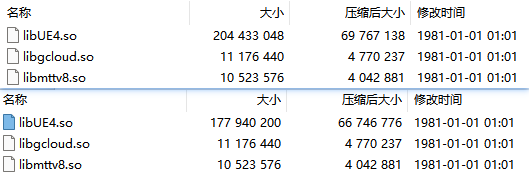
并且,它对内存的优化效果也非常显著:在Development下从190.49M - > 161.06M,减少了29.43M。
优化前(Development:190.49MB):
1 | ** MEMINFO in pid 16293 [com.xxx.yyy] ** |
优化后(Development:161.06MB):
1 | ** MEMINFO in pid 16294 [com.xxx.yyy] ** |
它对运行时性能是正面优化而不是降低,因为它通过减少运行时重定位的数量来提高代码加载速度和降低内存占用。
SDK 23
如果项目对SDK版本有要求,不能升级到28,也可以用另一种替代压缩参数,要求SDK版本>=23。
1 | AdditionalCompilerArguments += " -fPIC"; |
它也能够大幅压缩重定位表的大小(虽然不如RELE到几百K的级别),并且也能大幅降低so的内存占用:
压缩后(Development:3.41M):
1 | [ 8] .rela.dyn LOOS+0x2 000000000000aca0 0000aca0 |
运行时的内存情况(Development:163.19M),相较于原始190.49M,也降低了27.3M,比RELR略低:
1 | ** MEMINFO in pid 11492 [com.tencent.tmgp.fmgame] ** |
Shipping内存
当启用重定位表压缩后,Shipping包的总so运行时内存降低到了134.74M!
1 | ** MEMINFO in pid 13929 [com.xxx.yyy] ** |
资源裁剪
APK内文件
有一些第三方的插件,会往APK内拷贝文件,这也是可以优化的部分。
需要分析项目的实际使用情况处理:
- 剔除不必要的第三方组件
- 对于必须的组件,剔除不需要的文件
组件裁剪:以GVoice为例
如果项目集成了GCloud的组件,其中会拷贝至APK文件的组件中,GCloudVoice的模型文件占大头。
在APK内assets/GCloudVoice目录压缩后占了约13.5M: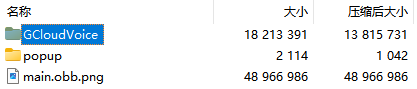
- wave_dafx_data.bin 是3d语音 不用3d功能可以移除
- wave_3d_data.bin 是3d语音 不用3d功能可以移除
- cldnn_spkvector.mnn 提取声纹的,默认不使用这个功能,可以移除
- libwxvoiceembed.bin 是文明语音的 不用文明语音可以移除
- libgvoicensmodel.bin 是噪声抑制算法模型,不能删
- decoder_v4_small.nn、encoder_v4_small.nn aicodec用的 不用aicodec的话可以删除
- dse_v1.nn、dse_v1_align.nn、dse_v1_mono.nn 这个是用于wwise下的新算法资源文件,如果有打包的大小限制,也可以去掉
可以把项目中未用到功能的模型文件剔除。另外从实现上,最好不要直接删除文件,而是修改GVoice_APL.xml的拷贝逻辑实现:
1 | <resourceCopies> |
游戏内资源
游戏内的资源就是UE引擎或组件依赖的资源/文件,会打包至PAK或拷贝至main.obb内的文件。
- PAK内:游戏内的资产,需要梳理哪些是非必要的,哪些是可以剔除或进行延迟加载的。
- DirectoriesToAlwaysStageAsNonUFS:不进PAK,但是会打包进main.obb里的
PAK内资源
更准确地描述是:安装包内PAK的资源。
引擎必要的资源都在pakchunk0中,除了pakchunk0外,UE可以把利用PrimaryAssetLabel拆分的Chunk打包至安装包外。
但对于pakchunk0中的资源或文件,依然要进行优化:
- 仅保留引擎必要的资源(
/Engine中的关键资产、ini、GlobalShader、项目ShaderLibrary、启动地图、GameFramework资产,等等),在我之前的文章(UE资源管理:引擎打包资源分析)有更详细的介绍。 - 剔除非启动阶段必须的资源
- 改造引擎延迟加载部分文件(如L10N本地化语言的加载)
- 拆分启动阶段与游戏内资源(如字体),游戏内字体单独打包且走动态下载
引擎本身的拆包逻辑也有较大的局限性,比如ShdaerLibrary之类的,默认整个项目生成一个,当规模庞大后,它也将成为优化包大小的瓶颈。这部分内容的详情可以查看我之前的另一篇文章(资源管理:重塑UE的包拆分方案)。
除此之外,还需要在资源管理和打包阶段,能够将Android的所有资源从安装包内剔除,转为动态下载/挂载的机制,并且不能够影响IOS。
当使用诸如PrimaryAssetLabel拆分pak时,引擎为Android提供了内置的把Pak从安装包内剔除的方法:
1 | ; Config/DefaultEngine.ini |
但官方仅在Android平台有支持,对于其他平台就没那么方便了。在之前的文章中曾介绍过,我开发的HotChunker扩展可以很容易地实现通用的包过滤方案,为全平台支持自定义的进包控制策略。
StageAsNonUFS
在引擎的打包配置中,有一项DirectoriesToAlwaysStageAsNonUFS,它是指定目录不打包进PAK,但是会打包进main.obb里的,目前引擎内只有Content/Movies目录会被拷贝至main.obb中。
而在打包时的读取的Ini,也是具有层级逻辑的,所以对于打包时的配置,依然能够对不同平台进行区分!如果想要在Android/IOS进行区分,也可以利用这个机制做到。
可以把打包策略做如下调整:除非必要的视频(如启动时立即播放的),可以把其余的游戏内MP4单独打包时PAK中,转为动态下载。
这样可以大幅减少APK内MP4的大小,也能够使MP4进行热更。
优化效果
综合上面多种对包大小优化手段后,顺利将游戏的APK大小1.23G降低到130M,原始so大小从258M降低到了132M。
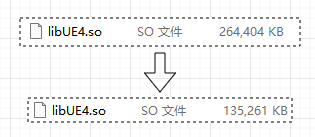
运行时内存也降低了数十M!并且包含了完整的第三方组件、游戏功能,资源可走动态下载,使安装包本体变成一个极小化的下载器,便于传播和分发。
实际采用哪些优化策略要结合实际项目的具体需要,以及对包体大小和性能的平衡来选择,如inline控制和编译优化级别、资源的极致化裁剪(L10N等)还需要对引擎进行改造等。
额外资料
本文中提到的博客内历史文章:
UE构建系统相关的扩展阅读:
其他外部资料:
- Epic官方有一篇优化包大小的文档:Reducing Packaged Game Size,可以与本文结合使用。
- 上架GooglePlay平台,有明确的大小要求:GooglePlay的应用大小限制。

