从C语言过来觉得C++03和OO的特性简直不能更爽,最近着重看了一下C++11的新特性,觉得有好多很棒的语法糖啊!用起来也很爽啊。
列表值序列
列表初始化
作为C++11新标准的一部分,**列表初始化(用花括号来初始化变量)**得到了全面应用。这种方式用起来确实是非常非常舒服的,比如vector模板想要初始化,要么使用一个容器初始化它,要么将其初始化为N个元素的值()。
列表初始化能够防止窄化转换,其含义是:
- 如果一个整型存不下另一种整型的值,则后者不会转换为前者。例如char可以转换到int,但int不能转换到char
- 如果一个浮点型存不下另一个浮点型的值,则后者不会转换为前者。例如float可以转换为double,但double不能转换到float
- 浮点值不能转换为整型值
- 整型值不能转换为浮点值
1 | // C++03标准,容器的构造函数 |
C++11标准支持的列表初始化方式:
列表初始化的形式为C c{element-List};或者C c={element-List};
注意:一定要使用花括号,使用圆括号来进行初始化是另一种完全不同的含义。
当我们使用auto关键字从初始化器推断变量的类型时,没必要采用列表初始化的方式。而且如果初始化器是{}列表,则推断到的数据类型肯定不是我们想要的结果。
当使用auto时,不要使用列表初始化,在auto中=是更好的选择,除非你明确知道得到的是你想要的结果。
1 | auto z1{99}; // z1 的类型是initializer_list<int> |
另外,当我们构建某些类的对象时,可能有两种形式:
- 提供一组初始值
- 提供几个实参
注意区分下面两个表达式的区别:
1 | // 一定要完全区分这两种含义 |
1 | int ival{10}; |
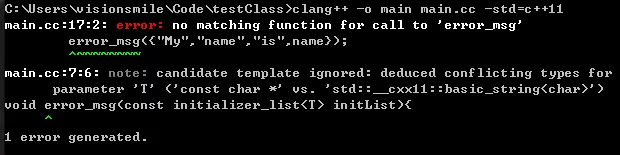
以上代码编译时如果不加std=c++11会产生四个错误:
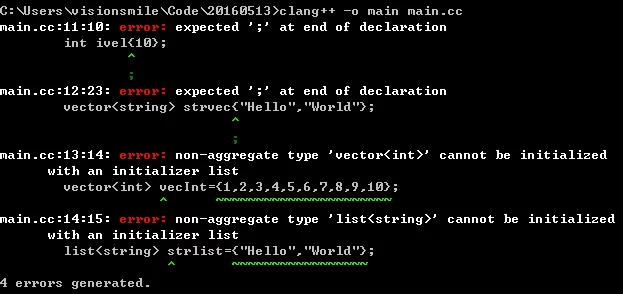
使用C++11的标准就要加上std=c++11,在编译就不会出错了。
运行并输出上面初始化的对象和容器:
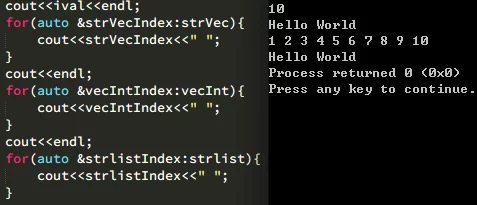
初始值列表
C++新标准规定使用花括号括起来的初始值列表作为赋值运算语句的右侧运算对象。
1 | vector<int> intVec; |
列表赋值语句不能用于窄化转换:
1 | int k; |
如果左侧运算对象是内置类型,那么初始值列表最多只能包含最多只能包含一个值,而且该值即使转换的话其所占空间也不应大于目标类型空间。类型转换还是参照详细分析下C++中的类型转换
无论左侧对象的类型是什么,初始值列表都可以为空。此时编译器创建一个值初始化的临时变量并将其赋值给左侧运算对象。
一个由{}限定的列表可以作为下述形参的实参:
- 类型
std::initializer_list<T>,其中列表的值能隐式地转换成T - 能用列表中的值初始化的类型
- T类型数组的引用,其中列表的值能隐式地转换成T
1 | template<class T> |
如果存在歧义性,则initializer_list参数的函数被优先考虑。
1 | template<class T> |
之所以优先选择具有initializer_list参数的函数,是因为如果根据列表的元素数量选择函数的话会让选择的过程显得非常混论。在重载解析额时候,很难把所有可能引起混淆的形式都排除干净,但是当遇到{}列表的参数时给initializer_list参数最高的优先级能最大限度地避免混淆。
列表初始化返回值
C++11规定函数可以返回花括号包围的值的列表。
由初始值列表的概念可得,列表为空,对内置类型进行值初始化,否则返回的值由函数的返回类型决定。
1 | vector<string> process(int x){ |
运行结果为:X > 0,Yes
关联容器的列表初始化
当定义一个map时,必须既指明关键字类型又指明值类型;而定义一个set时,只需指明关键字类型,因为set中没有值。
每个关联容器都定义了一个默认构造函数,它创建一个指定类型的空容器。也可以将关联容器初始化为另一个同类型容器的拷贝,或是从一个值范围来初始化关联容器,只要这些值可以转化为容器所需类型就可以。
在新标准下,我们可以对关联容器进行值初始化:
1 | // 空容器 |
列表初始化pair的返回类型
想象有一个函数需要返回pari。在新标准(C++11)下,我们可以对返回值进行列表初始化。
1 | pair<string,int> process(vector<string> &v){ |
若v不为空,我们返回一个有v中最后一个string及其大小组成的pair。否则,隐式构造一个空的pair并返回它。
在较早的C++版本中,不允许花括号包围的初始化器来返回pair这种类型的对象,必须显式地构造返回值:
1 | if(!v.empty()){ |
nullptr常量
在C++11之前,都是使用字面值0或者NULL来将指针初始化/赋值为空指针。
其中NULL是定义在cstdlib中的预处理器变量,其值为0,当用到一个预处理器变量时,预处理器会自动地将它替换为实际值,因此用NULL初始化指针和用0初始化指针是一样的。
把int型变量赋值给指针是错误的操作,即使该变量的值恰好为0也不行。
1 | int *p1=0; // 将p1初始化为字面值常量0 |
C++11标准引入了nullptr字面值常量可以用来将指针初始化为空指针。
nullptr是一种特殊类型的字面值,它可以被转换成任意其他的指针类型。
使用nullptr来初始化指针:
1 | int *p=nullptr; //等价于int *p=0; |
注意:使用未初始化的指针是运行错误的重要原因之一。应该初始化所有的指针,并且将一个指针delete之后应该立即将其置为空指针,否则再对其访问有可能会造成错误(悬垂指针)。
constexpr
constexpr变量
常量表达式(const expression)**是指值不会改并且在编译过程**就能得到计算结果的表达式。
很显然,字面值属于常量表达式,用常量表达式初始化的const对象也是常量表达式。
一个对象或表达式是不是常量表达式由它的数据类型和初始值共同决定的。
当constexpr出现在函数定义中时,它的含义是“如果给定了常量表达式作为实参,则该函数应该能用在常量表达式中”。而当constexpr出现在对象定义中时,它的含义是“在编译时对初始化器求值”。
1 | const int MAX_NUM=20; //MAX_NUM是常量表达式 |
C++11标准规定,允许将变量声明为constexpr类型以便由编译器验证变量的值是否是一个常量表达式。
声明为constexpr的变量必须是一个常量,并且必须用常量表达式初始化。
1 | constexpr int ival=20; //20是常量表达式 |
constexpr指针
在constexpr声明中如果定义了一个指针,限定符constexpr仅对指针有效,与指针指向的对象无关。
constexpr把它所定义的指针对象置为顶层const(指针不可修改,指向对象可修改)。
1 | // p是一个指向整型常量的指针,指针可修改,指向对象不可修改 |
constexpr函数
constexpr函数(constexpr function)是指能用于常量表达式的函数,函数必须足够简单才能在编译时求值。
定义constexpr函数的方法与其他类似,不过需要遵循几项规定:
- 函数的返回类型以及所有形参的类型都得是字面值
- 函数体中必须只有一条return语句
- 没有循环也没有局部变量
- constexpr不能有副作用(不能向非局部对象写入内容)
- 允许递归和条件表达式
也就是说constexpr函数应该是一个纯函数。
1 | int glob; |
1 | constexpr int new_sz(){return 42;} |
编译器把constexpr函数的调用替换成其结果值。为了能在编译过程随时展开,constexpr函数被隐式地指定为内联函数。
constexpr函数体内也可以包含其他的语句,只要这些语句在运行时不执行任何操作就行。
constexpr函数中可以有空语句、类型别名以及using声明。
我们允许constexpr函数的返回值并非一个常量:
1 | // 如果scale接收的参数是一个常量表达式,则scale(const-parameter)也是常量表达式 |
当scale的实参常量表达式时,它的返回值是常量表达式,反之则不然。
1 | //正确,scale(2)的返回值是常量表达式,编译器用相应的结果值替换对scale函数的调用 |
constexpr函数不一定返回常量表达式。
1 | size_t i=10; |
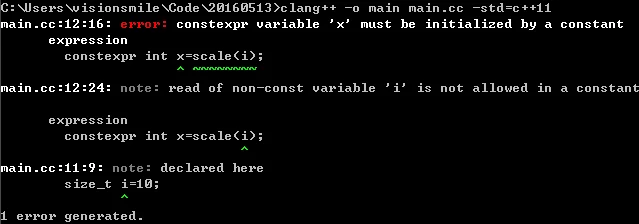
constexpr可以返回一个引用或指针:
1 | constexpr const int* addr(const int& r){return &r;} // OK |
但是这违背了constexpr函数作为常量表达式求值要求的初衷。
constexpr函数之外的条件表达式不会再编译时求值,这意味着他可以请求运行时求值。
1 | constexpr int check(int i) |
constexpr构造函数
与普通的constexpr函数相比,constexpr构造函数有所区别:只允许简单地执行成员初始化操作。
尽管构造函数不能为const(如果成员函数为const则意味着不能修改类内数据成员的值),但是字面值常量类的构造函数可以使constexpr函数。
一个字面值常量类必须至少提供一个constexpr构造函数,构造函数必须足够简单才能生命成constexpr,其中“简单”的的含义是它的函数体必须为空且所有成员都是潜在的常量表达式初始化。
constexpr构造函数可以声明成=default函数(编译器合成默认构造函数)的形式或者是=delete(删除函数)的形式。否则constexpr构造函数就必须既符合构造函数的要求(意味着不能包含返回语句),又符合constexpr函数的要求(意味着它能够拥有的唯一可执行语句就是返回语句)。
综上所述,constexpr构造函数体必须是空的。
1 | class Debug{ |
constexpr必须初始化所有的数据成员,初始值使用constexpr构造函数或是一条常量表达式。
constexpr构造函数用于生成constexpr对象以及constexpr函数的参数或返回类型:
1 | constexpr Debug io_sub(false,true,true); //调试io |
对于成员函数来说,constexpr隐含了const的意思。
1 | // const没有显式写的必要 |
地址常量表达式
全局变量等静态分配的对象的地址是一个常量。而该地址是由链接器赋值的,而非编译器。因此编译器并不知道这类地址常量的值是多少,这就限制了指针或者引用类型的常量表达式的使用范围。例如:
1 | constexpr const char* p1="HelloWorld"; |
类型推导
C++11引入了两种类型推导方式——auto和decltype,不过他们具有不同的作用。
auto的作用:推导等号右侧表达式(结果)的类型。
decltype的作用:通过现有的表达式来获取其类型。
decltype和auto的重要区别:
- decltype使用的表达式是一个变量时返回该变量的类型(包括const和引用在内),而auto返回的是表达式的最终结果的类型(类型转换和忽略顶层const属性)
- decltype的结果类型与表达式形式密切联系。
auto类型说明符
C++作为一个静态类型语言,需要在定义变量时明确知道变量的类型。
1 | int ival=10; |
C++11引入了新的类型说明符auto,用它能够让编译器替我们去分析表达式所属的类型。
与原来那些只对应一种特定类型的说明符不同,auto让编译器通过初始值来推算变量的类型。
注意:auto定义的变量必须有初始值。
使用auto说明符推断类型时有时候和初始类型并不完全一致,编译器会适当地改变结果来使其更符合初始化规则。参照我的这篇博文详细分析下C++中的类型转换
注意:使用引用类型实际上是使用引用的对象,特别是当做初始值的时候,真正参与初始化的其实是引用对象的值。
1 | int ival_1=10; |
auto一般会忽略掉顶层const属性,同时底层const则会保留下来
1 | int i=100; |
如果希望推断出的auto类型是一个顶层const,需要明确指出:
1 | const auto f=ci; |
设置一个类型为auto的引用时,初始值中的顶层常量属性仍然保留。
1 | auto &g=ci; //g是一个整型常量引用,绑定到ci |
decltype类型指示符
C++11标准引入了第二种类型说明符decltype,它的作用是选择并返回操作数的数据类型。在此过程中,编译器分析表达式并得到它的类型,却不实际计算表达式的值。
1 | decltype(f()) sum=x; //sum的类型就是函数f的返回类型 |
decltype处理顶层const和引用的方式与auto有些不同。
如果decltype使用的表达式是一个变量,则decltype返回该变量的类型(包括const和引用在内)。
1 | const int ci=0,&cj=ci; |
decltype和引用
如果decltype使用的表达式不是一个变量,则decltype的返回表达式结果对应的类型。
1 | // decltype的结果可以使引用类型 |
如果是解引用操作,则decltype得到的是引用类型。
解引用可以得到指针所指向的对象,而且还能给这个对象赋值。因此decltype(*p)的结果类型是int&而非int.
对于decltype所用的表达式来说,如果变量名加上一对括号,则得到的类型与加括号时会有所不同。
如果decltype使用的是一个不加括号的变量,则得到的结果就是该变量的类型;如果给变量加了一层或多层括号,编译器会把它当做是一个表达式。变量是一种可以作为赋值语句左值的特殊表达式,所以这样的decltype就会得到引用类型。
1 | //decltype的表达式如果是加上了括号的变量,结果将是引用 |
使用auto和decltype来简化声明
1 | int ia[4][4]; |
随着auto和decltype的引入,就能够尽可能地避免在数组前面加上一个指针类型了。
1 | //输出ia中每个元素的值,每个内层数组各占一行 |
using类型别名
在C++11之前我们使用typedef来定义类型别名。
1 | typedef double idouble; //idouble是double的同义词 |
C++11规定了一种的的别名声明方法using来定义类型。
1 | using idouble=double; |
关键字using作为别名声明的开始,其后紧跟别名和等号,其作用是把等号左侧的名字规定成等号右侧类型的别名。
类型别名简化多维数组的指针
1 | using int_array=int[4]; |
范围for语句
在c++11之前,如果我们想要遍历一个容器,就需要使用迭代器来遍历容器中的所有元素。
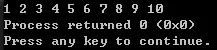
1 | vector<int> vecInt={1,2,3,4,5,6,7,8,9,10}; |
运行结果:
范围for语句的语法格式为:
1 | for(declration:expression) |
其中expression部分是一个对象,用于表示一个序列。declration部分负责定义一个变量,该变量将被用于访问序列中的基础元素。每次迭代,declration部分的变量会被初始化为expression部分的下一个元素值。
与上面使用迭代器的做法不同的是,不需要对declration解引用,因为其本身就为一个对象,可以直接访问,但是,其只是expression对象中基础元素的一个副本,修改其值不会改变expression对象中的数据,如果想要修改expression对象中的数据,应该将declration定义为引用。
1 | // 代码实现 |
除法的舍入规则
C++语言的早期版本允许结果为负值的商向上或者向下取整,C++11新标准规定商一律向0取整(直接切除小数部分)
根据取余运算的定义,如果m和n是整数,且n非0,则表达式(m%n)*n+m%n的求值结果与m相等。
1 | int m,n; |
隐含的含义就是,如果m%n不等于0,则它的符号与m相同。
C++早期版本(C++11之前),允许m%n的符号匹配n的符号,而且商向负无穷一侧取整,这一方式已经在新标准中禁止使用了。
除了-m导致溢出的情况,其他时候(-m)/n和m/(-n)都等于-(m/n),m%(-n),(-m)%n等于-(m%n)。
1 | 21%6; /*结果是3*/ 21/6; /*结果是3*/ |
sizeof
sizeof运算符用来用字节计算右边表达式并返回字节数(constexpr)。
sizeof的两种形式:
1 | sizeof (type) // 返回该类型在当前系统上的大小(byte) |
用于类对象成员
C++11新标准允许我们使用作用域操作符(::)来获取类成员的大小。
通常情况下只有通过对象才能访问到类的成员,但是sizeof运算符无需我们提供一个具体的对象,因为要想知道类成员的大小无需真的获取该成员。
1 | // 获取vector<int>的类型大小 |
用于不同对象得到的结果
下面并非C++11的部分,列举一下sizeof对于不同的对象获取的结果:
- 对char或者类型为char的表达式执行sizeof结果为1
- 对引用类型执行sezeof运算得到被引用对象所占空间的大小
- 对指针执行sezeof运算得到的指针本身所占空间的大小
- 对解引用指针执行sizeof运算得到的是指针指向对象所占空间的大小,指针不需要有效(悬垂指针和野指针也都可以进行sizeof操作)
- 对数组运算得到的是整个数组所占空间的大小,等价于对数组中所有的元素各执行一次sizeof运算并将所得结果求和。注意:sizeof运算不会把数组转换成指针来处理
- 对string对象或者vector对象执行sizeof运算只返回该类型固定部分的大小,不会计算对象中的元素占用了多少空间。
尾置返回类型
尾置返回类型跟在形参列表后面并以一个->符号开头。为了表示函数整整的返回类型在形参列表之后,我们在本应该出现返回类型的地方放置一个auto.
1 | // func接收一个int类型的实参,返回一个指针,该指针指向含有10个整数的数组。 |
任何函数的定义都能使用尾置返回,但是这种形式对于返回类型比较复杂的函数有效,比如返回类型是数组的指针或者数组的引用。
尾置返回类型的必要性源于函数模板的声明,因为其返回类型依赖于参数。
1 | template<class T,class U> |
类的构造
类内初始化
C++11标准规定,可以为数据成员提供一个**类内初始值(in-class initializer)**。
创建对象时,类内初始化将用于初始化数据成员。没有初始值的将被默认初始化
1 | struct Date{ |
类内初始化必须放在花括号里边,或者放在等号右边,一定不能使用圆括号。因为在类内使用圆括号会有歧义——是data memebr initialization还是member function declaration?
类对象成员的类内部初始化
当我们总希望类内的类成员具有默认值的时候,我们可以使用C++11的新标准——把这个默认值声明称一个类内初始值。参照上面的类内初始化
1 | class test{ |
使用=default生成默认构造函数
在C++11之前的标准中,当我们为类定义了一个构造函数(哪怕不是默认构造函数),则编译器就不会再为我们生成的一个默认构造函数了。
1 | class test{ |
当我们即需要默认构造函数也需要其他形式的构造函数时,我们必须为默认构造函数显式声明,因为编译器不会为我们合成默认构造函数。
但是在C++11中我们可以使用=default来要求编译器为我们生成一个默认构造函数。
但是不要期望编译器合成的默认构造函数会对数据成员初始化。具体可以参照这篇博文——关于编译器生成默认构造函数的一些误区
1 | class test{ |
=default既可以和声明一起出现在类的内部,也可以作为定义出现在类的外部。
与其他函数一样,如果=default在类的内部,则默认构造函数时内联的,如果它在类的外部,则默认情况下不是内联的。
委托构造函数
C++11新标准扩展了构造函数的初始值功能,使得我们可以定义所谓的委托构造函数(delegating constructor)。一个委托构造函数使用它所属类的其他构造函数执行它自己的初始化过程,或者说把它自己的一些(或全部)初始化职责委托给其他构造函数。
和其他构造函数一样,一个委托构造函数也有一个成员初始值的列表和一个函数体。在委托构造函数内,成员值列表只有一个唯一的入口,就是类名本身。和其他的成员初始值一样,类名后面紧跟圆括号括起来的参数列表,参数列表必须与类中另一个构造函数相匹配。
1 | class test{ |
但一个构造函数委托给另一个构造函数时,受委托的构造函数的初始值列表和函数体被依次执行。在上面的test类中,受委托的函数体恰好是空的。加入函数体包含有代码的话,将先执行这些代码,然后控制权才会交还给委托者的代码。
如:
1 | class test{ |
当我们声明一个test的对象:
1 | test X; |
会输出:

可以看出,是先执行完委托构造函数体中的代码然后才会执行委托者中的代码。
使用string对象当做文件流对象的文件名
1 | // 打开文件,每次写之前定位到文件末尾 |
在之前的C++标准中,文件名参数(也就是上面代码中的"out.txt")只允许是C风格数组。
C++11中文件名既可以是C风格数组也可以是string对象。
即,上面的代码也可以这么写:
1 | string filename("out.txt"); |
STL容器相关特性
array和forward_list容器
| 容器名 | 含义 |
|---|---|
| array | 固定大小数组。支持快速随机访问。不能添加或删除元素。 |
| forward_list | 单向链表。只支持单向顺序访问。在链表任何位置进行插入/删除操作速度都很快 |
forward_list和array是C++11标准新增加的容器类型。
与内置数组相比,array是一种更加安全、更容易使用的数组类型。
与内置类型类似,array对象的大小是固定的。因此array不支持添加和删除元素以及改变容器大小的操作。
array是个模板,它可以存放任意数量、任意类型的元素。它还可以直接处理异常和const对象。
1 | array<int,3> x={1,2,3}; |
与内置类型相比,std::array有两个明显的优势:
- 它是一种真正的对象类型(可以执行赋值操作)。
- 不会隐式地转换为指向元素的指针(传递数组退化为指针)。
但是stad::array也有不足,我们无法根据初始化器的长度推断元素的数量。
1 | // 3个元素 |
更多std::array支持的操作可以看这里:std::array - cppreference
forward_list的设计目标是达到最好与最好的手写单向链表数据结构相当的性能。
因此,forward_list没有size操作,因为保存或计算其大小就会比手写链表多出额外的开销。
对于其他容器而言,size保证是一个快速的常量时间的操作。
- forward_list有自己专门的
emplace和insert - forward_list不支持
push_back和emplace_back操作
initializer_list形参
如果函数的实参数量未知,但是全部实参的类型都相同,那么就可以使用initializer_list类型的形参。
initializer_list是一种标准库类型,用于表示特定类型值的数组。定义在同名(initializer_list)头文件中。与vector一样initializer_list也是一种 模板类型,定义initializer_list对象时必须说明列表中所含元素的类型。
| initializer_list提供的操作 | 含义 |
|---|---|
| initializer_list |
默认初始化:T元素类型的空列表 |
| initializer_list |
lst的元素和初始值一样多;lst的元素是对应初始值的副本;列表中的元素是const |
| lst2(lst)lst2=lst | 拷贝或赋值一个initializer_list对象不会拷贝列表中的元素,拷贝后原始列表和副本共享元素 |
| lst.size() | 列表中的元素数量 |
| lst.begin() | 获取指向lst中首元素的指针 |
| lst.end() | 获取指向lst中尾元素的下一位置的指针 |
1 | template <class T> |
也可以使用列表值序列{}来传递给initializer_list形参的函数:
1 | // 注意,这段代码在template <class T>下会产生错误,直接使用initializer_list<string>则会成功 |
也可以用initializer_list存储已有的相同类型的变量,然后传递给函数:
1 | template <class T> |
对initializer_list对象的引用是const引用,获取initializer_list对象的指针也是const指针。
下面的内容查自cppreference——initializer_list:
An object of type std::initializer_list is a lightweight proxy object that provides access to an array of objects of typeconst T.
A std::initializer_list object is automatically constructed when:
- a braced-init-list is used in list-initialization, including function-call list initialization and assignment expressions
- a braced-init-list is bound to auto, including in a ranged for loop
Initializer lists may be implemented as a pair of pointers or pointer and length. Copying a std::initializer_list does not copy the underlying objects.
| Member type | Definition |
|---|---|
| value_type | T |
| reference | const T& |
| const_reference | const T& |
| size_type | std::size_t |
| iterator | const T* |
| const_iterator | const T* |
从上面的表可以看出,如果使用&或迭代器传递initializer_list对象,我们是不能够修改其值的。
by Value可以,但是,修改的对象就不是实参了。
容器的非成员函数swap
在C++11中,容器既提供成员函数版本的swap也提供非成员函数版本的swap
而早期的标准版本只提供成员函数版本的swap。非成员函数版本的swap在泛型编程中非常重要。统一使用非成员函数版本是个好习惯。
swap是交换两个相同类型容器的内容。调用swap之后,两个容器中的元素将会交换。
1 | vector<string> svec1(10); //10个元素的vector |
运行结果:

交换两个容器的内容的操作保证很快——元素本身并未交换,swap只是交换了两个容器的内部数据结构。
除了array外,swap不对任何元素进行拷贝、删除或者插入操作,因此可以保证在常数时间内完成。
元素不会移动的事实意味着,除了string外,指向容器的迭代器、引用和指针在swap之后都不会失效。他们仍然指向swap操作之前所指向的那些元素。但是在swap之后,这些元素已经属于不同的容器了。
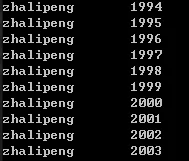
1 | vector<string> svec1{"My","name","is","zhalipeng"}; //10个元素的vector |
注意:对一个string容器调用swap操作会导致迭代器、指针和引用失效。
与其他容器不同,对两个array容器进行swap操作会真正交换他们的元素。因此交换两个array所需的时间与array中元素的数目成正比。
因此对于array容器,在swap之后,指针、引用和迭代器所绑定的元素保持不变,但元素值已经与另外一个array中对应的元素的值进行了交换。
容器的insert返回类型
我们可以使用容器的成员函数insert来插入一段范围内的元素。
| insert版本 | 含义 |
|---|---|
| c.insert(p,t) | 在迭代器p指向的元素之前创建一个值为t的元素,返回指向新添加元素的迭代器 |
| c.insert(p,b,e) | 将迭代器b和e指定的范围内的元素插入到迭代器p指向的元素之前 |
| c.insert(p,n,t) | 在迭代器p指向的元素之前插入n个值为t的元素,返回指向新添加元素的第一个元素的迭代器;若n为0则返回p |
在新标准下,接收元素个数或返回的insert版本返回指向第一个新加入元素的迭代器。在旧的标准中,这些操作返回void。
1 | vector<string> svec1{"My","name","is","zhalipeng"}; //10个元素的vector |
emplace操作
新标准引入了三个新成员——emplace_front、emplace和emplace_back,这些操作构造而不是拷贝元素。
这些操作分别对应push_front、insert和push_back,允许我们将元素放置在容器头部、一个指定位置之前或容器尾部。
- forward_list有自己专门的
emplace和insert
- forward_list不支持
push_back和emplace_back操作
- vector和string不支持
push_front和emplace_front
当调用push或者insert成员函数时,我们将元素类型的对象传递给它们,这些对象被拷贝到容器中。而当我们调用一个emplace成员函数时,则是将参数传递给元素类型的构造函数。emplace成员使用这些参数在容器中管理的内存空间中直接构造元素。
例如:
1 | //假定我们现在有一个类test |
如果使用emplace_back添加test对象:
1 | vector<test> x; |
运行结果:
1 | // 使用push_back来试试 |
可以看出,上面emplace_back的调用和push_back的调用都会创建一个新的test对象。在调用emplace时,会在容器管理的内存空间中直接创建对象。而调用push_back则会创建一个局部的临时对象,并将其压入容器中。
emplace函数的参数根据元素类型而变化,参数必须与元素类型的构造函数相匹配。
1 | vector<test> x; |
string数值转换函数
C++11中引入了多个函数,可以实现数值数据与标准库string之间的转换。
| 函数 | 操作含义 |
|---|---|
| to_string(val) | 一组重载函数,返回数值val的string表示。val可以是任何算数类型。对每个浮点类型和int或更大的整型都有相应版本的to_string。 与往常一样,小整型会被提升。 |
| stoi(s,p,b) stol(s,p,b) stoul(s,p,b) stoll(s,p,b) stoull(s,p,b) |
返回s的起始子串(表示整数内容)的数值,返回值类型分别是int/long/long long/unsigned long/unsigned long long。b表示转换所用的基数,默认值为10。p是一个指针,用来保存s中第一个非数值字符的下标,p默认为0,即函数不保存下标。 |
| stof(s,p) stod(s,p) stold(s,p) |
返回s的起始子串(表示浮点数内容的数值)返回值类型分别是float/double/long double。参数p的作用与整数转换函数中的一样。 |
1 | //to_string |
运行结果:
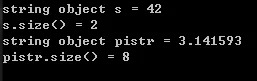
将double转换为string会发生浮点舍入——具体内容参照IEEE754
由string到其他算数类型的转换:
1 | // stod |
运行结果:
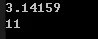
上面用到了两个成员函数:
1 | // substr()返回本字符串的一个子串,从index开始,长num个字符。如果没有指定,将是默认值 string::npos。这样,substr()函数将简单的返回从index开始的剩余的字符串。 |
管理容量的成员函数
| 成员函数 | 操作行为 | 适用范围 |
|---|---|---|
| c.shrink_to_fit() | 请将capacity()减少为size()同样的大小 | 只适用于vector,string和deque |
| c.capacity() | 不重新分配内存的话,c可以保存多少元素 | 只适用于vector和string |
| c.reserve(n) | 分配至少能容纳n个元素的内存空间 | 只适用于vector和string |
reserve操作并不会改变容器中元素的数量,它影响vector预先分配多大的内存空间。
只有当需要的内存空间超过当前容量时,reserve调用才会改变vector的容量。如果需求大小大于当前容量,reserve至少分配与需求一样大的内存空间(可能更大)。
如果需求大小小于或等于当前容量,reserve什么也不做。特别是需求大小小于当前容量时,容器不会退回内存空间,因此在调用reserve之后,capacity将会大于或等于传递给reserve的参数。
这样,调用reserve永远不会减少容器占用的内存空间。
类似的resize成员函数只改变容器中元素的数目,而不是容器的容量。同样不能使用resize来减少容器预留的内存空间。
在C++11标准中,我们可以调用shrink_to_fit来要求vector、deque、string退回不需要的内存空间。
此函数指出我们不再需要任何多余的内存空间。但是具体的实现可以选择忽略此请求,也就是说,调用shrink_to_fit也不保证一定退回内存空间。
capacity和size的区别
- size:指容器中已经保存的元素的数目
- capacity:指在不重新分配内存的前提下可以保存多少元素
1 | vector<int> x; |
上面的代码在不同平台的编译下结果:
| 编译环境 | 结果 |
|---|---|
| Visual Studio2015 | 0 0 |
| Clang 3.7.0 x86_64-w64-windows-gnu | 0 0 |
| g++ 5.2.0 x86_64-posix-seh-rev1 | 0 0 |
无序容器
C++11中定义了四个无序关联容器(unordered associative container)。
分别为:unordered_map,unordered_set,unordered_multimap,unordered_multiset,在使用相应的无序容器时也需要包含其相应的头文件(容器名)。
这些容器不是使用比较运算符来组织元素,而是使用一个哈希函数(hash function)和关键字(key)类型==运算符。在关键字类型的元素没有明显的序关系的情况下,无序容器是非常有用的。在某些应用中,维护元素的序列代价非常高,此时无序容器也很有用。
如果关键字类型固有就是无序的,或者性能测试发现问题可以用哈希技术解决,就可以使用无序容器。
使用无序容器
除了哈希管理操作之外,无序容器还提供了与有序容器相同的操作(fins、insert等)。这意味着能够用在map和set上的操作也可以用在unordered_map和unordered_set。类似的,无序容器也有允许重复关键字的版本。
通常可以用一个无序容器替换对应的有序容器,反之亦然。但是,由于元素未按顺序存储,一个使用无序容器的程序的输出通常会与使用有序容器的版本不同。
例如,可以使用unordered_map写一个单词计数程序:
1 | unordered_map<string,size_t> word_count; |
注意,因为是无序容器,所以残次输出的顺序是不太可能按照读入的顺序输出的。
管理桶
无序容器在存储上组织为一组桶,每个桶保存零个或多个元素。无序容器使用一个哈希函数将元素映射到桶。为了访问一个元素,容器首先计算元素的哈希值,它指出应该搜索哪个桶。容器将具有一个特定哈希值的所有元素都保存在相同的桶中。如果容器允许重复关键字,所有具有相同关键字的元素也都会在一个桶中。因此,无序容器的性能依赖于哈希函数的质量和桶的数量大小。
对于相同的参数,哈希函数必须总是产生相同的结果。理想情况下,哈希函数还能将每个特定的值映射到唯一的桶。但是将不同的关键字映射到相同的桶也是允许的。
当一个桶保存多个元素时,需要顺序搜索这些元素来查找我们想要的那个。计算一个匀速的哈希值和在桶中搜索通常都是很快的操作。但是如果一个桶中保存了很多的元素,那么查找一个特定元素就需要大量的比较操作。
无序容器提供了一组管理桶的函数。这些成员函数允许我们查询容器的状态以及在必要时强制容器进行重组。
| 管理桶的函数 | 操作含义 |
|---|---|
| 桶接口 | |
| c.bucket_count() | 正在使用的桶的数目 |
| c.max_bucket_count() | 容器能容纳最多的桶的数目 |
| c.bucket_size(n) | 第n个桶中有多少个元素 |
| c.bucket(k) | 关键字为k的元素在哪个桶中 |
| 桶迭代 | |
| local_iterator | 可以用来访问桶中元素的迭代器类型 |
| const_local_iterator | 桶迭代器的const版本 |
| c.begin(n)/c.end(n) | 桶n的首元素迭代器和尾后迭代器 |
| c.cbegin(n)/c.cend(n) | 与前两个函数类似,但返回的是const_local_iterator |
| 哈希策略 | |
| c.loadfactor() | 每个桶的平均元素数量,返回float值 |
| c.max_load_factor() | c试图维护平均桶大小,返回float值。c会在需要时添加新的桶,以使得load_factor<=max_load_factor重组存储,使得bucket_count>=n |
| c.rehash(n) | 重新存储。使得bucket_count>=n且bucket_cout>size/max_load_factor |
| c.reserve(n) | 重新存储。使得c可以保存n个元素而不必rehash |
无序容器对关键字类型的要求
默认情况下,无序容器使用关键字类型的==运算符来比较元素,它们还使用一个hash<key_type>类型的对象来生成每个元素的哈希值。标准库为内置类型(包括指针)提供了hash模板。还为一些标准库类型,包括string和只能指针类型定义了hash。因此我们可以直接定义关键字是内置类型(包括指针类型)、string还是智能指针类型的无序容器。
注意:虽然无序容器支持关键字是内置类型(包括指针类型)、string还是智能指针类型。但是我们不能直接定义
关键字类型为自定义类型的无序容器。与容器不同,不能直接使用哈希模板,而必须提供我们自己的hash模板版本。会在
模板特例化部分讲到如何实现自己的hash版本。
我们不使用默认的hash,而是使用另一种方法,类似于为有序容器重载关键字类型的默认比较操作。
为了能让我们的自定义类型用作无序容器的关键字,我们需要提供函数来替代==运算符和hash计算函数。
1 | // 假定我们现在有一个自定义类book |
可以从定义这些重载函数开始:
1 | size_t hasher(const book &bk){ |
如果我们没有重载类的==操作符:
1 | using BK_multiset=unordered_multiset<book, decltype(hasher)*,decltype(eqOq)*>; |
重载了==操作符:
1 | unordered_set<book,decltype(bkHash)*> bkset(10,bkHash); |
lambda表达式
我们可以向一个算法传递任何类别的可调用对象(callable object)**。
对于一个对象或者表达式,如果可以对其使用调用运算符(),则称它为可调用的。
在C++11之前,我们可以使用的可调用对象为函数和函数指针,还有重载了调用运算符的类。
C++11引入了一种新的可调用对象——lambda**
一个lambda表达式表示一个可调用的代码单元。我们可以理解为一个未命名的内联函数。
lambda表达式又叫做匿名函数。
与任何函数类似,一个lambda具有一个返回类型(必须使用尾置返回类型)、一个参数列表和一个函数体。
但函数不同,lambda可能定义在函数内部。
1 | [capture list](parameter list)-> return type{function body} |
capaure list(捕获列表),是一个lambda所在函数中定义的局部变量的列表。parameter list、return 和function body与普通函数一样,分别表示形参表,返回类型和函数体。
也可以忽略lambda的参数列表和返回类型,在lambda中忽略括号和参数列表等价于指定一个空参数列表。但必须永远包含捕获列表和函数体。如果忽略返回类型,lambda根据函数体中的代码推断出返回类型。如果函数体只是一个return语句,则返回类型从返回的表达式的类型推断而来。否则返回类型为void。
1 | auto f=[]{return 42;}; |
如果lambda的函数体包含任何单一return语句(c++14可以多个但必须同类型)之外的内容且未指定返回类型,则返回void。
注意:lambda除了能作为参数外,还能用于初始化一个声明为auto或者std::function<R(AL)>的变量。其中R是它的返回类型,AL是它的类型参数列表。
1 | // error,无法在推断一个auto变量的类型之前使用它(递归) |
如果只是想给lambda起个名字,而不递归使用可以使用auto。
如果一个lambda什么也不捕获,则可以将它赋值给一个指向正确类型的函数的指针。
1 | double (*p1)(double)=[](double a){return sqrt(a);}; |
向lambda传递参数
与一个普通函数类似,调用一个lambda时给定的实参被用来初始化lambda的形参。
通常,实参和形参的类型必须匹配。但与普通函数不同,lambda不能有默认形参,因此,一个lambda调用实参的数目必须与形参数目相等。一旦形参初始化完毕,就可以执行函数体了。
1 |
|
执行结果:
stable_sort的原型:更多详细的内容看以参照这里——stable_sort - cppreference
1 | //参数frist和last表示范围内的元素,comp是一个谓词参数,是比较函数,如果第一个参数小于第二个参数,返回true |
所以我们可以用lambda来替代函数cmp(lambda本来也就是函数的形式,不过它是匿名函数)
使用捕获列表
谓词
在介绍lambda的捕获列表之前,我们先来熟悉一下谓词的概念。
谓词是一个可调用的表达式,其返回结果是一个能用做条件的值(bool)。
标准库算法用到的谓词分为两类:一元谓词(unary predicate,意味着它们只能接收单一参数)和二元谓词(binary predicate,意味着他们有两个参数)。接受谓词参数的算法对输入序列中的元素调用谓词。因此元素类型必须能够转换为谓词的参数类型。
虽然一个lambda可以出现在一个函数中,使用其局部变量,但它只能使用那些明确指明的变量。一个lambda通过将局部变量包含在其捕获列表中来指出将会使用这些变量。捕获列表指引lambda在其内部包含访问局部变量所需要的信息。
1 | int num=5; |
上面的代码中,lambda会捕获num用作lambda函数体中。
改写上面的代码,使其能够输出一个容器中所有长度大于X的元素。
1 | for (auto index = find_if(word.begin(), word.end(), [num](const string& a) {return a.size() >= num; }); index != word.end();) { |
运行结果:
lambda捕获和返回
当定义一个lambda时,编译器生成一个与lambda对应的新的(未命名的)类类型。
当向一个函数传递一个lambda时,同时定义一个新类型和该类型的一个对象:传递的参数就是此编译器生成的类类型的未命名对象。
当我们用auto定义一个用lambda初始化的变量时,定义了一个从lambda生成的类型的对象。
默认情况下,从lambda生成的类都包含一个对应该lambda所捕获变量的数据成员。类似于任何普通类的数据成员,lambda的数据成员也在lambda对象创建时被初始化。
选择是值捕获还是引用捕获的依据与函数参数完全一致。
如果我们希望向捕获的对象写入内容,或者捕获的对象很大,则应该使用引用。对于lambda来说,还应该注意它的有效期可能会超过它的调用者。
当把lambda传递给其他线程时,一般来说通过**值捕获([=])**更优:通过引用或者指针访问其他线程的栈内容是一种危险的操作(对于正确性和性能都是如此),更严重的是,视图访问一个已终止的线程的栈内容会印发极难发现的程序错误。
如果你想要捕获可变参数模板,可以使用...:
1 | template<typaname ...Var> |
值捕获
类似参数传递,变量的捕获方式也可以是值或者引用。
与传值参数类似,采用值捕获的前提是变量可以拷贝。与参数不同,被捕获的变量的值在lambda创建时拷贝,而不是调用时拷贝。
1 | int x=11; |
注意:使用值捕获是不能够直接在lambda中修改捕获的变量值的。
如果我们意图修改值捕获方式的对象值将会编译错误,但引用捕获不会:
1 | //值捕获 |
想要在lambda的函数体中修改捕获的值,可以使用引用捕获,也可以使用mutable修饰值捕获的lambda,后面介绍,在此先按下不表。
cppreference中这么写道:
Unless the keyword mutable was used in the lambda-expression, the function-call operator is const-qualified and the objects that were captured by copy are non-modifiable from inside this operator().
链接:Lambda functions (since C++11)
引用捕获
我们定义lambda时使用引用捕获的方式捕获变量。使用方法和在捕获对象前添加一个&号。
1 | int x=11; |
引用捕获和返回引用有着相同的问题和限制:如果我们采用引用方式捕获一个变量,就必须确保被引用对象在lambda执行的时候是存在的。
lambda捕获的都是局部变量(local),这些变量在函数结束之后就不复存在了。如果lambda可能在函数结束之后执行,捕获的引用指向的局部变量已经消失。
引用捕获有时候是必要的,比如,我们需要用lambda捕获一个ostream,因为IO对象不可复制,所以只能使用引用捕获。
也可以从一个函数返回lambda。函数可以直接返回一个可调用对象,或者返回一个类对象,该类含有可调用对象的数据成员。如果函数返回一个lambda,则与函数不能返回一个局部变量的引用类似,此lambda也不能包含引用捕获。
隐式捕获
除了显式列出我们希望使用的来自所在函数的变量之外,还可以让编译器很据lambda体中的代码来推断我们要使用那些变量(意味着,编译器只会捕获在函数体中用到的变量)。为了指示编译器推断捕获列表,应在捕获列表中写一个&或者=。&告诉编译器采用捕获引用方式,=则表示采用值捕获方式。
1 | int ival=11; |
还可以采用混合捕获方式,对某个变量采用某种捕获方式,其他的均为另一种捕获方式。
1 | int ival=11; |
当我们混合使用隐式捕获和显式捕获时,捕获列表中的第一个元素必须是一个&或者=。此符号指定了默认捕获方式为引用或值。
当混合使用隐式捕获和显式捕获时,显式捕获的变量必须使用与隐式捕获不同的方式。即,如果隐式捕获方式是值捕获,那么显式捕获的变量必须为引用捕获方式,反之亦然。
lambda的几种捕获方式
| 捕获方式 | 含义 |
|---|---|
| [] | 空捕获列表。lambda不能使用所在函数中的变量。一个lambda只有捕获变量后才能使用它们。 |
| [names] | names是一个逗号分隔的名字列表,这些名字都是lambda所在函数的局部变量。默认情况下,捕获列表中的变量都是被拷贝。名字前如果使用了&,则采用引用的捕获方式。 |
| [&] | 隐式捕获列表。采用引用捕获方式。lambda体中所使用的来自所在函数的实体都采用引用方式使用。 |
| [=] | 隐式捕获列表。采用值捕获方式。lambda体将拷贝所使用的来自所在函数的实体的值。 |
| [&,identifier_list] | identifier_list是一个以逗号分隔的列表,包含0个或多个来自所在函数的变量。这些变量采用值捕获方式,而任何隐式捕获的变量都采用引用方式捕获。捕获列表中可以出现this。identifier_list中的名字前面不能使用&。 |
| [=,identifier_list] | identifier_list红的变量采用引用方式捕获,而任何隐式捕获的变量都采用值捕获方式。identifier_list中的名字不能包括this,且这些名字之前必须使用&。 |
lambda位于成员函数中捕获this
当lambda被用在成员函数中时,我们该如何访问类的成员呢?
可以吧this添加到捕获列表中,这样类的成员就位于可被捕获的名字集合中了。
1 | class Request{ |
成员通过引用的方式捕获,也就是说[this]意味着成员是通过this访问的,而非拷贝到lambda中。
[this]与[=]互不兼容,因此稍有不慎就可能在多线程程序中产生竞争条件。
可变lambda
默认情况下,对一个值被拷贝的变量,lambda不会改变其值。
如果我们希望能改变一个被捕获的变量的值,就必须在参数列表后加上mutable。因此,可变lambda能省略参数列表。
对于引用捕获,不需要显式在参数列表后加mutable关键字,但是对于值捕获方式一定需要。
1 | int ival=11; |
但是对于采用值捕获方式的lambda就一定要使用mutable了
1 | int ival=11; |
一个lambda引用捕获的变量能否被修改依赖于此引用指向的是一个const类型还是一个非const类型。
1 | const int ival=11; |
而采用值捕获方式同样具有这个问题:
1 | const int ival = 11; |
所以,采用值捕获的对象的类型与函数局部变量的类型是完全一样的。
指定lambda返回类型
默认情况下,如果一个lambda体包含return之外的任何语句,则编译器假定此lambda返回void。与其他的void函数类似,被推断返回void的lambda不能返回值。
lambda表达式的返回类型能由lambda表达式本身推断得到而普通函数无法做到这一点。
如果lambda的主体部分只包含一条return语句,则该lambda的返回类型是该return表达式的类型。(C++14中可以在未显式指定类型的情况下具有多个返回语句,但必须保证每个return返回的为同一类型,详细看后面)。
首先要熟悉以下lambda的几种定义形式:
| Syntax |
|---|
| [ capture-list ] ( params ) mutable(optional) exception attribute -> ret { body } |
| [ capture-list ] ( params ) -> ret { body } |
| [ capture-list ] ( params ) { body } |
| [ capture-list ] { body } |
| Explanation | Effect |
|---|---|
| mutable | allows body to modify the parameters captured by copy, and to call their non-const member functions |
| exception | provides the exception specification or the noexcept clause for operator() of the closure type |
| attribute | provides the attribute specification for operator() of the closure type |
| capture-list | a comma-separated list of zero or more captures, optionally beginning with a capture-default.Capture list can be passed as follows (see below for the detailed description):**[a,&b]** where a is captured by value and b is captured by reference.**[this]** captures the **this** pointer by value**[&]** captures all automatic variables odr-used in the body of the lambda by reference**[=]** captures all automatic variables odr-used in the body of the lambda by value**[]** captures nothing |
| params | The list of parameters, as in named functions, except that default arguments are not allowed (until C++14). ifauto is used as a type of a parameter, the lambda is a generic lambda (since C++14) |
| ret | Return type. If not present it’s implied by the function return statements ( or void if it doesn’t return any value) |
| body | Function body |
考虑如下代码:
1 | //将一个序列中的所有值转换为其绝对值 |
执行结果:
transform算法是定义在algorithm头文件中的,函数原型如下:
1 | template< class InputIt, class OutputIt, class UnaryOperation > |
上面的代码中,我们传递给transform一个lambda,它返回其参数的绝对值。lambda体是单一的return语句,返回一个表达式的结果,我们无需指定返回类型,因为可以根据条件运算符的类型推断出来。
但是,如果我们使用看似等价的if语句,就会产生错误:
1 | // C++11中错误的做法,不支持隐式推导多个返回表达式 |
但是我使用clang++和g++编译并不会报错(WTF)。
通过查资料发现:Lambda functions (since C++11) - cppreference和C++14 Language Extensions
C++11 permitted automatically deducing the return type of a lambda function whose body consisted of only a single return statement:
1 | // C++11 |
This has been expanded in two ways. First, it now works even with more complex function bodies containing more than one return statement, as long as all return statements return the same type:
1 | // C++14 |
Second, it now works with all functions, not just lambdas:
1 | // C++11, explicitly named return type |
Of course, this requires the function body to be visible.
Finally, someone will ask: “Hmm, does this work for recursive functions?” The answer is yes, as long as a return precedes the recursive call.
See also:
- [N3638] Jason Merrill: Return type deduction for normal functions.
总得来说就是:
C++14可以在不使用尾置返回(multiple return)的情况下,具有多个返回表达式,但是这些返回值的类型必须相同。
但是C++11并没有这个性质,所以我推测,可能是编译器的bug…
参数绑定
对于那种只在一两个地方使用的简单操作可以使用lambda表达式,但是如果我们需要在很多地方使用相同的操作,通常应该定义一个函数,而不是通过多次编写相同的lambda表达式。
如果lambda的捕获列表为空,通常可以用函数来代替它。
如介绍lambda时使用的样例代码那样:
1 | int num=5; |
我们既可以使用lambda(代码如上)也可以定义一个函数来实现::
1 | bool check_size(const string &s,string::size_type sz){ |
但是我们不能将这个函数用作find_if的一个参数。如前文介绍lambda所述,find_if需要接收一个一元谓词参数,因此传递给find_if的参数必须为接收单一参数。为了使用check_size来代替lambda,必须解决如何向sz形参传递一个参数的问题。
1 | //check_size的调用形式 |
标准bind函数
通过bind函数我们可以解决向check_size传递一个长度参数的问题。
bind标准库函数,它定义在头文件functional中。可以将bind函数看做一个通用的函数适配器,它是一个可调用对象,生成一个新的可调用对象来”适应“原对象的参数列表。
调用bind的一般形式:
1 | auto newCallable=bind(callable,arg_list); |
其中newCallable本身一个可调用对象,arg_list是一个逗号分隔的参数列表,对应给定的callable的参数。即,当我们调用newCallable时,newCallable会调用callable,并传递给它arf_list中的参数。
arg_list中的参数可能包含形如_n的名字,其中n是一个整数这些参数是“占位符”,表示newCallable的参数,他们占据了传递给newCallable的参数的“位置”。数值n表示生成的可调用对象中参数的位置:_1为newCallable的第一个参数,_2为第二个参数,以此类推。
使用placeholders名字
注意:名字_n都定义在一个名为placeholders的命名空间中,而这个命名空间本身定义在std命名空间。
所以,当我们在bind中使用_1、_2这样的参数时一定要使用std::placeholders命名空间:
1 | // 该命名空间中的所有名字都可以在程序中使用 |
否则,编译时会报错:
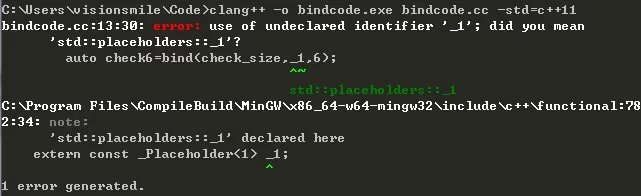
通过bind来绑定参数
通过bind来绑定check_size的sz参数从而生成一个接受一个参数的谓词(一元谓词)。
前面已经讲到,我们需要将接收两个参数的check_size传递给必须接收一元谓词的函数find_if,所以我们需要使用bind生成一个对check_size的进行调用操作的对象。
1 | //check6是一个可调用对象,接受一个steing类型的参数 |
此bind调用只有一个占位符,表示check6只接受单一参数。占位符出现在arg_list的第一个位置,表示check6的此参数对应check_size的第一个参数。此参数是一个const_string&。因此,调用check6必须传递给它一个string类型的参数,check6会将此参数传递给check_size。
1 | string s="hello"; |
通过使用gprof可以看到,check_size被调用了一次。
1 | % cumulative self self total |
使用bind,我们可以将原来基于lambda的find_if调用:
1 | auto wc=find_if(words.begin(),worda.end(),[sz](const string &a){return a.size()>=sz;}); |
替换为使用check_size的版本:
1 | auto wc=find_if(words.begin(),words.end(),bind(check_size,_1,sz)); |
此bind调用生成一个可调用对象,将check_size的第二个参数绑定到sz的值。当find_if对words中的string调用这个对象时,这些对象会调用check_size,将给定的string和sz传递给它。因此,find_if可以有效地对输入序列中每个string调用check_size,实现string的大小与sz的比较。
bind的参数
前面提到,我们可以用bind来修正参数的值。更一般的情况是,可以使用bind绑定给可调用对象中的参数或重新安排其参数顺序。
例如,f是一个可调用对象,他有5个参数,则下面对bind的调用:
1 | auto g=bind(f,a,b,_2,c,_1); |
上面的代码会生成一个可调用对象,它有两个参数,分别用占位符_1和_2和表示。这个新的可调用对象将他自己的参数作为第三个和第五个参数传递给f。f的第一个、第二个和第四个参数分别绑定到给定的值a、b和c上。
传递给g的参数按位置绑定到占位符。即,第一个参数绑定到_1,第二个参数绑定到_2。因此,当我们调用g时,其第一个参数将被传递给f作为最后一个参数,第二个参数将被传递给f作为第三个参数。
实际上这个调用会将g(_1,_2)映射为f(a,b,_2,c,_1)。即,对g的调用会调用f,用g的参数代替占位符,再加上绑定的参数a、b和c。例如,调用g(X,Y)会调用f(a,b,Y,c,X);
用bind重排参数顺序
注意:sort定义在algorithm头文件中,使用前需包含。
我们可以使用sort对容器排序,首先定义一个二元谓词。
1 | bool isShorter(const string &s1,const string &s2){ |
我们可以使用sort来排序一个vector
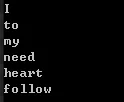
1 | vector<string> words{"I","need","to","follow","my","heart"}; |
执行后的结果为:
1 | I to my need heart follow |
排序结果是由升序排列的,但是如果我们想要降序排列呢?只能修改isShorter函数实现吗?
其实不然,可以使用bind来重排参数的顺序来实现。
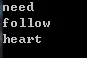
1 | // 将sort谓词的第一个参数作为isShorter的第二个参数 |
执行后的结果为:
1 | follow heart need to my I |
绑定引用参数(ref(_n))
默认情况下,bind的那些不是占位符的参数被拷贝到bind返回的可调用对象中。但是,与lambda相似,优势对有些绑定的参数我们希望以引用方式传递,或是要绑定参数的类型无法拷贝(IO对象不能被拷贝或赋值)。
例如,为了替换一个捕获ostream(不能被拷贝)的lambda:
1 | // os是一个局部变量,引用一个输出流 |
我们可以很容易的编写一个函数来完成相同的工作:
1 | osteram &print(osteram &os,const string &s,char c){ |
但是,不能直接用bind来代替对os的捕获:
1 | // 错误,不能拷贝os |
原因在于bind拷贝其参数,而我们不能拷贝一个ostream。如果我们希望传递给bind一个对象而又不拷贝它,就必须使用标准库ref函数:
1 | for_each(words.begin(),words.end(),bind(print,ref(os),_1,' ')); |
函数ref返回一个对象,包含给定的引用,此对象时可以拷贝的。标准库中还有一个cref函数,生成一个保存const引用的类。与bind一样,函数ref和cref也均是定义在functional头文件中。
向后兼容:参数绑定
旧版本的标准库(C++11之前)定义了两个分别名为bind1sd和bind2nd的函数。类似bind,这两个函数接受一个函数作为参数,生成一个新的可调用对象,该对象调用给定函数,并将绑定的参数传递给他。但是,这些函数分别只能绑定第一个或第二个参数。由于这些函数局限性太强,新标准中已经弃用(deprecated)。所谓被弃用的特性就是在新版本中不再支持的特性。在新的C++程序中应该使用bind。

