一些C++中比较能令人迷惑或者用法比较奇特的示例记录。
显式限定数组实参的元素个数
数组在作为函数参数传递时会退化为指针:
A declaration of a parameter as “array of type” shall be adjusted to “qualified pointer to type”.
以及前面已经提到的:
int x[3][5];Here x is a 3 × 5 array of integers. When x appears in an expression, it is converted to a pointer to (the first of three) five-membered arrays of integers.
这意味着数组作为参数传递时会丢失边界(C/C++的原生数组本来也就没有边界检查…)。
1 | void funcA(int x[10]){} |
其对应的中间代码为:
1 | ; Function Attrs: nounwind uwtable |
如果数组边界的精确数值非常重要,并且希望函数只接收含有特定数量的元素的数组,可以使用引用形参:
1 | void funcC(int (&x)[10]){} |
其中间代码为:
1 | ; Function Attrs: nounwind uwtable |
如果我们使用数组元素个数不等于10的数组传递给funcC,会导致编译错误:
1 | // note: candidate function not viable: no known conversion from 'int [11]' to 'int (&)[10]' for 1st argument. |
也可以使用函数模板参数来指定函数接收参数的数组大小:
1 | template<int arrSize> |
使用时:
1 | int x[12] |
启用编译器的改变符号的隐式类型转换警告
1 | if((unsigned int)4<(unsigned int)(int)-1){ |
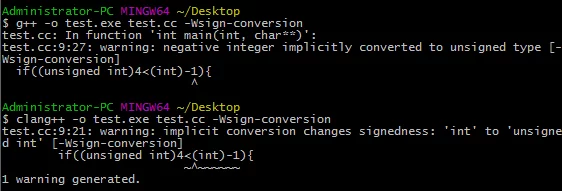
if中的那段表达式是为true的(输出yes),而且编译时也不会发出警告。
虽然我们指定了(int)-1,但是当将unsigned int和int比较时会发生隐式转换。即:
The usual arithmetic conversions are performed on operands of arithmetic or enumeration type.
1 | ((unsigned int)4<(unsigned)(int)-1)==true |
Warnings about conversions between signed and unsigned integers are disabled by default in C++ unless -Wsign-conversion is explicitly enabled.
通过启用-Wsign-conversion就可以看到警告了(建议开启)。
该参数的作用为:
Warn for implicit conversions that may change the sign of an integer value, like assigning a signed integer expression to an unsigned integer variable. An explicit cast silences the warning. In C, this option is enabled also by -Wconversion.
更多的GCC警告选项可一看这里Warning-Options
断言(assert)
assert Defined in header
If NDEBUG is defined as a macro name at the point in the source code where <assert.h> is included, then assert does nothing.
If NDEBUG is not defined, then assert checks if its argument (which must have scalar type) compares equal to zero.
1 |
cppreference - assert
assert只在Debug模式中有效,使用release模assert什么都不做了。
因为在VC++里面,release会在全局定义NDEBUG
下面的代码在VS中使用debug和release模式分别编译并输入>100的数,会有不一样的结果(release不会)
1 |
|
无效的引用
通常情况下我们创建的引用就是有效的,但是也可以人为因素使坏…
1 | char* ident(char *p) { return p; } |
这是UB的行为。
in particular, a null reference cannot exist in a well-defined program, because the only way to create such a reference would be to bind it to the “object” obtained by indirection through a null pointer,which causes undefined behavior.
数组的引用
1 | void f(int(&r)[4]){ |
对于数组引用类型的从参数来说,元素个数也是其类型的一部分。通常只有在模板中才会使用数组引用,此时数组的引用可以通过推断得到。
1 | template<class T,int N> |
这么做的后果是调用f()所用的不同类型的数组有多少个,对应定义的函数有多少个。
忽略函数参数的顶层cv-qualifier
为了与C语言兼容,在C++中会自动忽略参数类型的顶层cv-qualifier。
例如下面的函数在C++会报重定义错误,而不是重载:
1 | // 类型是int(int) |
不论对于哪种情况,允许修改实参也好,不允许修改实参也好,它都只是函数调用者提供的实参的一个副本。因此调用过程不会破坏调用上下文的数据安全性。
因为函数的签名规则如下:
<function>name, parameter type list (8.3.5), and enclosing namespace (if any)
而函数的parameter-type-list会移除top-level cv-qualifier:
[ISO/IEC 14882:2014 §8.3.5.5]After producing the list of parameter types, any top-level cv-qualifiers modifying a parameter type are deleted when forming the function type. The resulting list of transformed parameter types and the presence or absence of the ellipsis or a function parameter pack is the function’s
parameter-type-list.
char作为数组下标时当心unsigned/signed
当char类型用作数组下标时,一定要先转unsigned char(因为char通常是有符号的(依赖实现定义))。不能直接转int或unsigned int,会数组下标越界。
1 |
|
struct tag (*[5])(float)
The type designated as ‘‘struct tag (*[5])(float)’’ has type ‘‘array of pointer to function returning struct tag’’. The array has length five and the function has a single parameter of type float. Its type category is array.
new一个指针数组
1 | int TEN=10; |
底层(Low-Level)const和顶层(Top-Level)const
底层const(Low-Level const):表示指针所指的对象是一个常量。
顶层const(Top-Level const):表示指针本身是个常量。顶层const可以表示任意的对象是常量,这对于任何数据类型都适用。
1 | int ival=0; |
其实我有一个简单的区分的方法:看const修饰的右边是什么。
- 对于
int const *x=std::nullput;,const修饰的是*x,因为x是指针,我们就暂且把此处的*x当做解引用来看,他就代表x所指向的对象,则它就是底层const。 - 反之亦然,
int * const x=std::nullptr;,因为const修饰的是指针x,所以它就是顶层const。
在构造函数中传递this指针的危害
如果我们在构造函数中将this指针传递给其它的函数,有可能会引发这样的问题:
1 | struct C; |
看起来上面的代码似乎没什么问题,但是我们构造一个const C的时候,有可能会出现这样的问题:
1 | const C cobj; |
上面的代码会编译通过并可以在no_opt中修改常量对象cobj的成员i的值。
在一个常量对象构造的时候将其this指针传递给其他函数,这意味着我们可以修改该常量中的对象的值,这是不合乎标准的。
During the construction of a const object, if the value of the object or any of its subobjects is accessed through a glvalue that is not obtained, directly or indirectly, from the constructor’s this pointer, the value of the object or subobject thus obtained is unspecified.
所以还是不要在构造函数中写将this指针传递出类外的东西(最好还是只初始化数据成员吧)…
获取当前执行程序的绝对路径
有两种方法:
1 |
|
这种方法有一个弊端:如果将可执行程序添加至系统的PATH路径,则获取到的是在某个目录执行时该目录的路径。
另一种方法是通过Windows API来获取:
1 | const string getTheProgramAbsPath(void){ |
在此种方式下不论是否将该程序添加至系统的PATH路径以及在何处执行,都会获取该可执行程序在系统中存放的绝对路径。
一个奇葩的using用法
1 | using foofunc=void(int); |
上面的代码里:
1 | foofunc foo; |
是声明一个函数foo,可以看一下目标文件中的符号信息(省去无关细节):
1 | $ clang++ -c testusing.cc -o testusing.o -std=c++11 |
通过gcc工具链中的c++filt可以还原目标文件中的符号:
1 | $ c++filt _Z3fooi |
但是并没有定义,直接链接会产生未定义错误。
右值引用
1 | int x=123; |
其IR代码为:
1 | # 使用值123初始化x |
从而实现非拷贝行为,其行为类似于将一个对象的地址赋值给一个指针。
其实右值引用的作用就是给临时对象续命——将引用绑定到一个临时对象,不会带来额外的拷贝操作。
实现同样续命行为的还有const T&:
1 | int x=123; |
和上面的示例在LLVM下会产生一模一样的IR代码。
一个数组名字例子
1 | int a[]={1,2,3,4,5}; |
到底有几种传参方式
大多数人都觉得在C++函数中有以下三种传参方式:
- **传值(by value)**:形参的值是实参的拷;
- **传引用(by reference)**:形参是实参的别名;
- **传指针(by pointer)**:传递指向对象的指针给形参;
实际上,C++中只有两种传参方式:传值、传引用。
因为**传指针(by pointer)**也是传值的一种,形参的值也只是实参的一份拷贝,只是形参和实参都是指针而已。
在C++之父的著作:《The C++ Programming Language 4th》中写道:
Unless a formal argument(parameter) is a reference, a copy of the actual argument is passed to the function.
传指针(by value)**只是一种利用指针的性质来实现防止拷贝带来开销的一种技巧,而不是一种传参方式**。
定义拷贝/赋值与析构函数的三大法则
如果一个类需要自定义的拷贝构造函数、拷贝赋值操作符、析构函数中的任何一个,那么他往往同时需要三者。
因为编译器生成的隐式定义的copy constructor和operator=语义是逐成员拷贝(memberwise)的,所以如果编译器生成的操作不能够满足类的拷贝需求(比如类成员是具有管理某种资源的句柄),使用编译器的隐式定义会具有浅拷贝,导致两个对象进入某种共享状态。
1 | struct A{ |
如果使用编译器生成的语义会使对象x和y内部共享一块内存,所以需要用户自己定义拷贝构造和拷贝赋值操作符,同样的原因,因为类成员持有某种资源,也需要用户自定义一个析构函数。
引用的实现
C++标准中是这么解释引用的:
**[ISO/IEC 14882:2014 §8.3.2]**A reference can be thought of as a name of an object.
但是标准中并没有要求应该如何实现引用这一行为(这一点标准中比比皆是),不过多数编译器底层都是使用指针来实现的。
看下列代码:
1 | int a=123; |
然后将其编译为LLVM-IR来看编译器的实际行为:
1 | %2 = alloca i32, align 4 |
可以看到,指针和引用在经过编译器之后具有了完全相同的行为。
适当使用编译器生成操作
在特殊成员函数的隐式声明及其标准行为中提到了编译器会隐式生成和定义六种特殊的成员函数的行为。
因为编译器生成的copy constructor和copy assigment operator均是具有memberwise行为的。所以当我们撰写的类使用浅拷贝可以满足的时候(值语义),没必要自己费劲再写相关的操作了,因为编译器生成的和你手写的一样好,而且不容易出错。
1 | struct A{ |
虽然当你没有显式定义一个copy constructor和copy assignment operator的时候编译器就会隐式定义,但是最好还是自己手动使用=delete指定。
编译器生成的和下面这样手写的一样:
1 | struct A{ |
显然自己手写容易出错,这样的行为可以放心地交给编译器来做。
STL容器中压缩容量和真正地删除元素
摘取自《C++编程规范:101条规则/准则与最佳实践》第82条。
压缩容器容量:swap魔术
1 | vector<int> x{1,2,3,4,5,6,7}; |
真正地删除元素:std::remove并不执行删除操作
STL中的std::remove算法并不真正地从容器中删除元素。因为std::remove属于algorithm,只操作迭代器范围,不掉用容器的成员函数,所以是不可能从容器中真正删除元素的。
来看一下SGISTL中的实现(SGISTL的实现太老,没有用到std::move):
1 | template <class _InputIter, class _Tp> |
可以看到它们只是移动元素的位置,并非真正地把元素删除,只是将不该删除的元素移动到容器的首部,然后返回新的结束位置迭代器。
等于是把删除的部分移动到了元素的尾部,所以要真正地删除容器中所有匹配的元素,需要用erase-remove惯用法:
1 | c.erase(std::remove(c.begin(),c.end(),value),c.end()); // 删除std::remove之后容器尾部的元素 |
谨防隐藏基类中的重载函数
如果基类中具有一个虚函数func但是其又重载了几个非虚函数:
1 | struct A{ |
如果我们想要在B对象中使用非虚版本的func函数:
1 | B x; |
这是由于派生类在覆盖基类虚函数的时候会隐藏其他的重载函数,需要在B中显式引入:
1 | struct B:public A{ |
宏的替代
宏在预处理阶段被替换,此时C++的语法和语义规则还没有生效,宏能做的只是简单的文本替换,是极其生硬的工具。
C++中几乎从不需要宏。可以用const和enum定义易于理解的常量。用inline来避免函数调用的开销,用template指定函数系列和类型系列,用namespace避免名字冲突。
除非在条件编译时使用,其他任何时候都没有在C++中使用宏的正当理由。
类内内存分配函数
C++中类内的内存分配函数都是static成员函数:
Any allocation function for a class T is a static member (even if not explicitly declared static).
这意味着operator new/operator delete以及operator new[]/operator delete[]都被隐式声明为static成员函数。
异常安全
- 析构函数、operator new、operator delete不能抛出异常
- swap操作不要抛出异常
- 首先做任何可能抛出异常的事情(但不会改变对象重要的状态),然后以不会抛出异常的操作结束。
- 当一个被抛出的异常从throw表达式奔向catch子句时,所经之路任何一个部分执行的函数比从执行堆栈上移除其激活记录之前,都必须清理他所控制的任何资源。
- 不要在代码中插入可能会提前返回的代码、调用可能会抛出异常的函数、或者插入其他一些东西从而使得函数末尾的资源释放得不到执行。
指向类成员函数指针的cv版本
如果我们具有一个类A,其中具有重载的成员函数func,而他们的区别只是该成员函数是否为const,那么在定义一个指向成员函数的指针时如何分别?
1 | struct A{ |
如果我们只是创建一个A::func的指针,指向的只是non-const版本。
1 | void(A::*funcP)()=&A::func; |
想要指定const的版本,就需要在声明时指定const:
1 | void(A::*funcConstP)()const=&A::func; |
对于const的A对象要使用const的版本,对于non-const的A对象要使用non-const的版本,不能混用。
1 | const A x; |
STL中的compare操作实现
不同于C语言中的宏,使用C++中的模板(template)和谓词(Predicates)可以很轻易的写出泛型的比较操作。
在宏定义中还要注意参数的副作用,因为宏只是简单的替换,比如:
1 |
|
但是这个宏的实际操作这并不是我们所期待的行为。
幸运的是,在C++中我们可以使用模板来避免这种丑陋的宏定义,而且也可以传递一个自定义的谓词来实现我们的判断行为:
1 | struct Compare{ |
计算性构造函数
在某些情况下,可以通过创建构造函数的方式来提高成员函数的执行效率。
1 | struct String{ |
自身类型的using成员
怎么定义一个类的成员中能够获取到当前类类型的成员呢?
可以用下面这种写法:
1 | template<typename T> |
虽然有种强行搞事的意思…
std::vector的随机访问
std::vector可以随机访问,因为其重载了[]操作符,以及有at成员函数,则通常有下面两种方式:
1 | template<typename T> |
以上两种随机访问方式有什么区别?
顺序容器的
at(size_type)要求有范围检查。
**[ISO/IEC 14882:2014]**The member function at() provides bounds-checked access to container elements. at() throwsout_of_rangeif n >= a.size().
而operator[]标准中则没有任何要求。
可以来看一下一些STL实现(SGISTL)的源码对std::vector的operator[size_type]和at(size_type)的实现:
首先是at(size_type)的实现
1 | // at(size_type)的实现 |
可以看到,operator[]的随机访问并没有范围检查。
即上面的问题:
1 | x[0]; |
这两个的区别在于,若x不为空,则行为相同,若x为空,x.at(0)则抛出一个std::out_of_range异常(C++标准规定),而x[0]是未定义行为。
注意typedef和#define的区别
1 | typedef int* INTPTR; |
还是直接从IR代码来看吧:
1 | %6 = alloca i32*, align 8 |
注意%9不是i32*,它是一个i32的对象。
因为#define只是编译期的简单替换,所以在编译期展开的时候会变成这样:
1 |
|
即只有i3为int*,而i4则为int
为什么const object不是编译时常量?
1 | const int x=10; |
这里是可以的,在编译器优化下x会直接被替换为10
其中间代码如下:
1 | %6 = alloca i32, align 4 |
可以看到%7的分配时并没有使用%6,所以也并不依赖x这个对象,这个对象是编译期已知的。
但是,当我们这么写时,又如何编译期可知:
1 | int x; |
这里是由于编译器扩展,所以C++也支持VLA。但是可以看到const是没办法为编译期常量的。
继承层次中的类查询
在类的继承层次中,可能具有同一基类的几个不同的派生类,他们之间可能又互相继承派生出了几个继承层次,在这样的情况下如何判断某一个派生类的层次中是否继承自某一个类呢?
可以使用dynamic_cast来实现我们的要求,关于C++类型转换的部分可以看我之前的一篇文章:详细分析下C++中的类型转换。下面先来看一下dynamic_cast在C++标准中的描述(ISO/IEC 14882:2014):
The result of the expression
dynamic_cast<T>(v)is the result of converting the expression v to type T. T shall be a pointer or reference to a complete class type, or “pointer to cv void.” The dynamic_cast operator shall not cast away constness (5.2.11).
If C is the class type to which T points or refers, the run-time check logically executes as follows:
- If, in the most derived object pointed (referred) to by v, v points (refers) to a public base class subobject of a C object, and if only one object of type C is derived from the subobject pointed (referred) to by v the result points (refers) to that C object.
- Otherwise, if v points (refers) to a public base class subobject of the most derived object, and the type of the most derived object has a base class, of type C, that is unambiguous and public, the result points (refers) to the C subobject of the most derived object.
- Otherwise, the run-time check fails.
The value of a failed cast to pointer type is the null pointer value of the required result type. A failed cast to reference type throws an exception (15.1) of a type that would match a handler (15.3) of type
std::bad_cast(18.7.2).
所以我们可以对继承层次中的类指针执行dynamic_cast转换,检查是否转换成功,从而判断继承层次中是否具有某个类。
一个代码的例子如下:
1 |
|
可以从上面的代码中看到类Circle的继承层次: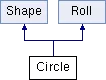
以及Square的继承层次:
上面的继承层次比较简单,但是当假设我们不知道Cricle和Square的具体继承层次时,那么如何判断Square中是否存在某一基类(如Roll)?
解决的办法就是上面提到的dynamic_cast!通过dynamic_cast转换到转换到要检测的类类型的指针,如果转换成功,dynamic_cast会返回从源类型转换到目标类型的指针,如果失败会返回一个空指针(之所以不使用引用是因为要处理可能会抛出异常的潜在威胁),这种转换并非是向上或者向下转型,而是横向转型。所以我们需要对dynamic_cast返回的对象(指针)作一个判断就可以得出检测目标的继承层次中是否存在要检测的类型。
但是,我觉得这种行为的适用场景十分狭窄,在良好的类设计下几乎不必要,如果你对自己所实现的类层次感到失控,那一定是糟糕的设计。
在使用列表初始化时initializer_List构造函数优先级比普通构造函数高
先来介绍两个基本概念:
List-initialization is initialization of an object or reference from a braced-init-list. Such an initializer is called an initializer list.
initializer-list constructor: A constructor is an initializer-list constructor if its first parameter is of typestd::initializer_list<E>or reference to possibly cv-qualifiedstd::initializer_list<E>for some type E, and either there are no other parameters or else all other parameters have default arguments (8.3.6).
Note: Initializer-list constructors are favored over other constructors in list-initialization (13.3.1.7).
1 |
|
[ISO/IEC 14882:2014 13.3.1.7 Initialization by list-initialization] When objects of non-aggregate class type T are list-initialized (8.5.4), overload resolution selects the constructor in two phases:
- Initially, the candidate functions are the initializer-list constructors (8.5.4) of the class T and the
argument list consists of the initializer list as a single argument. - If no viable initializer-list constructor is found, overload resolution is performed again, where the
candidate functions are all the constructors of the class T and the argument list consists of the elements of the initializer list.
If the initializer list has no elements and T has a default constructor, the first phase is omitted. In copy-list-initialization, if an explicit constructor is chosen, the initialization is ill-formed. [ Note: This differs from other situations (13.3.1.3, 13.3.1.4), where only converting constructors are considered for copy-initialization. This restriction only applies if this initialization is part of the final result of overload resolution. - end note ]
简单翻译一下就是,当一个类的构造函数参数是列表初始化(list-initialized),构造函数的重载解析分为了两步
- 优先匹配构造函数参数为initializer-list的构造函数,如果initializer-list中没有元素并且该类有一个默认构造函数,则该步被忽略。
- 如果找不到可行的initializer-list构造函数,重新执行重载解析,候选函数为Class的所有构造函数,参数列表由initializer-list的元素组成。
注意:在拷贝列表初始化(copy-initializer_list)语义下,如果重载决议选中的是explicit构造函数,则程序使ill-formed.
1 | class A{ |
而且,explicit构造函数会禁用initializer list的隐式转换。
1 | class A; |

